深度学习模型及其在声学音频领域的应用—以长短期记忆网络(Long Short-Term Memory, LSTM)为例
1、引言
长短期记忆网络(Long Short-Term Memory, LSTM)是一种特定类型的递归神经网络(Recurrent Neural Network, RNN),专为解决标准 RNN 在处理长序列数据时面临的梯度消失问题而设计。自提出以来,LSTM 因其卓越的时间序列处理能力,广泛应用于自然语言处理、语音识别、音频分类等领域。本文将详细介绍 LSTM 的原理、优缺点、适用场景,并探讨其在声学音频领域的应用及现状成果。
一个完整的卷积神经网络通常由输入层,卷积层,激活层,池化层和全连接层组成,几部分按一定顺序进行排列。在神经网络构建过程中,卷积层通常和激活层组成卷积模块,输入数据经过多个卷积模块和池化层输出用于分类的特征图。
2、长短期记忆网络(LSTM)的原理
2.1、 RNN 与梯度消失问题
递归神经网络(RNN)是一种能够处理序列数据的神经网络,通过循环连接,将前一时刻的输出作为当前时刻的输入,使得网络能够保留和利用历史信息。然而,标准 RNN 在处理长序列数据时,容易出现梯度消失或爆炸问题,导致网络无法有效学习长期依赖关系。这使得 RNN 在许多实际应用中性能受到限制。
2.2、 LSTM 的结构与工作机制
LSTM 通过引入“门”机制,有效缓解了 RNN 的梯度消失问题,使得网络能够捕捉和利用长期依赖关系。LSTM 单元主要由三个门(输入门、遗忘门、输出门)和一个细胞状态组成:
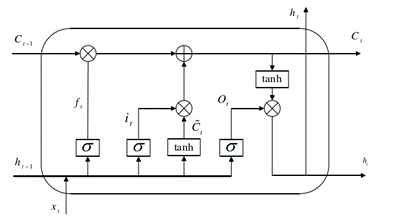
- 输入门(Input Gate):输入门决定了哪些新信息将被存储在细胞状态中。它包含两个部分:输入门的激活值(控制哪些信息会更新到细胞状态)和新候选值(用于更新细胞状态)
输入门的激活值:
新候选值:
其中,it 是输入门的输出,C~t 是新候选值,Wi 是输入门的权重矩,WC 是候选值的权重矩阵,bi和 bC是偏置项
- 遗忘门(Forget Gate):遗忘门决定了哪些信息将被丢弃。它的输出是一个在0到1之间的值,表示遗忘的程度,计算公式如下所示:
其中,ft 为遗忘门的输出,Wf 表示遗忘门的权重矩阵,ht−1 是前一时刻的隐藏状态,xt 是当前时刻的输入,bf 是遗忘门的偏置,σ 为 sigmoid 激活函数
- 输出门(Output Gate):输出门决定了当前时刻的隐藏状态 ht 需要输出什么信息。输出门的计算包括:输出门的激活值以及细胞状态的经过 tanh 激活函数处理的值,计算公式如下:
输出门的激活值:
隐藏状态:
其中,ot 是输出门的输出,Wo 是输出门的权重矩阵,bo 是输出门的偏置
- 更新细胞状态(Cell State):更新后的细胞状态 Ct 是通过将前一时刻的细胞状态 Ct−1 与输入门控制的候选值结合来计算的:
3、 卷积神经网络模型(CNN)的优势及局限性
3.1、优势
(1)长期依赖处理能力:LSTM 通过其门控机制,能够有效捕捉和保留长序列中的长期依赖信息,解决了标准 RNN 在处理长序列数据时的梯度消失问题。
(2)灵活性与适应性:LSTM 具有较强的灵活性,可以处理各种序列数据,包括变长序列和不同维度的输入输出,使其适用于广泛的时间序列任务。
(3)双向信息处理:通过双向 LSTM,网络能够同时利用过去和未来的信息,提高了对序列数据的理解和建模能力。
3.2、局限性
(1)计算复杂度高:LSTM 由于其复杂的门控机制和递归结构,计算成本较高,训练时间长,对计算资源要求较高。
(2)难以并行化:由于LSTM 的递归性质,其在处理长序列时的计算依赖前一时刻的输出,难以在现代 GPU 上进行高效并行计算,这限制了其在大规模数据上的应用。
4、小结
LSTM 算法在扬声器异音检测中展现了良好的应用前景,通过其强大的时间序列建模能力,有效地处理了扬声器音频信号中的长程依赖问题。然而,数据质量和数量、计算资源和实时性、模型解释性、异常类型处理以及模型融合等方面仍然存在改进的空间。未来的研究可以着重于优化模型结构、提高计算效率、增强模型的解释性和适应性,以进一步提升 LSTM 在扬声器异音检测中的性能和应用效果。