用两只麦克风,把异常声音“抠”出来:一种工程可落地的声学异常检测思路
翻译自《Abnormal sound detection by two microphones using virtual microphone technique》
作者:Kouei Yamaoka,Nobutaka Ono,Shoji Makino,Takeshi Yamada
发表于:APSIPA Annual Summit and Conference,2017 年 12 月
在工业现场做过声学或振动测试的人,几乎都会遇到这样一个现实问题:真正想抓的异常声音,即使并不大,但是周围的“正常声音”却异常顽强。风扇、流水、电机运转、背景音乐,虽然它们并不算故障,但是却在声能上占据绝对主导。只要算法稍微“粗一点”,这些正常声音就会把真正的异常彻底淹没。很多时候,问题并不是模型不聪明,而是前端声学条件根本不给你发挥的机会。苏州东原电子推出的👉AI异音异响检测系统👈,基于先进的机器听觉与深度学习算法,实现对电机、扬声器及各类旋转设备运行声音的实时分析与精准识别,让“不可见的故障”通过声音被快速捕捉。
本文所关注的,正是这样一个非常工程化、也非常现实的场景:在只有两个麦克风、背景噪声复杂、异常声音方向未知的情况下,如何尽可能稳定地把“异常事件”从声音里检测出来。论文的实验背景是居家养老监护,但它提出的方法,对工业设备异音检测同样有很强的参考价值。
为什么工业现场需要声学或振动异常检测
在产线和设备现场,声音和振动往往是最早暴露问题的信号。轴承早期损伤、电机轻微擦碰、滑轨卡滞、风扇叶片不平衡,都会先以声音或振动的形式出现。如果等电流、温度或停机报警,往往已经错过最佳干预时机。
但现实情况是,工业现场很少是“安静”的。设备本身就在持续发声,多台设备同时运行,环境反射复杂,甚至还有人为操作噪声。这就导致一个结果:很多基于简单能量阈值的检测方法,要么误报频繁,要么为了降低误报而把真正的异常也一并漏掉。
传统方法在工程中的尴尬
从算法角度看,工程上常见的思路大致有两类。一类是基于先验模型的,比如明确知道目标是什么声音,利用模板、特征或机器学习模型去“认”它。另一类是基于空间信息的,比如阵列波束形成,把已知方向的正常声源压下去,剩下的就当作异常。
问题在于,这两类方法在工程现场都各有短板。前者要求你事先知道异常声音长什么样,而真实世界里的异常往往是“第一次出现”。后者对硬件要求很高,理论上要压制 N 个正常声源,就至少需要 N+1 个麦克风,这在很多嵌入式设备、便携设备甚至端检工位上都不现实。很多设备只有双通道麦克风,这一点在论文中被反复强调。
于是就出现了一个很典型的工程矛盾:我们既想利用空间信息,又没有足够的麦克风;我们不想假设异常声音的类型和方向,但又希望系统对环境变化足够鲁棒。
这篇论文提出了什么新思路
论文给出的思路可以用一句话概括:在只有两个真实麦克风的情况下,通过“虚拟麦克风”把阵列在算法层面“变多”,再结合子空间噪声抑制,把稳定存在的正常声音压下去,最后只用最朴素的声能判断去抓异常。
这里面有两个关键点。第一,不去建模异常声音本身,而是尽可能准确地建模“正常声音空间”。第二,不执着于传统阵列的物理限制,而是在信号域中构造出“虚拟的观测通道”,让原本在双通道下不可用的子空间方法重新变得可用。
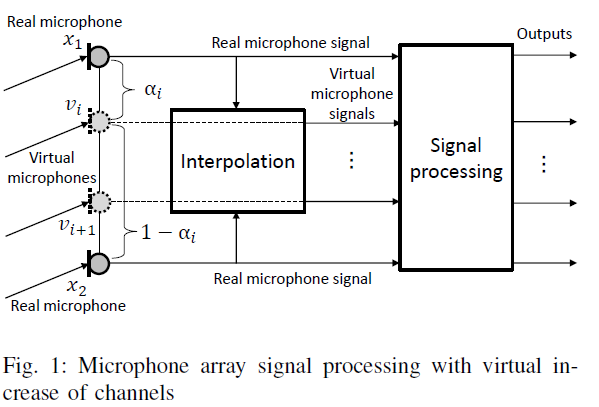
关键方法的工程化理解
从工程角度看,整个流程可以拆成三步。第一步,把双通道麦克风信号变换到时频域,这是所有现代声学算法的基础。第二步,通过虚拟麦克风技术,把两个真实通道插值扩展成多个“等效通道”。第三步,在这些通道上做子空间分析,把长期稳定存在的正常声源投影到被抑制的子空间里。
所谓子空间方法,本质上是在回答一个问题:在一段“只有正常声音”的时间里,这些声音主要分布在哪些空间维度上。一旦这个空间被学到,新来的信号中,只要不完全落在这个空间里,就会在剩余子空间中显现出来。异常声音正是这样一种“不合群”的成分。
在传统阵列中,如果麦克风数量不够,这种方法是行不通的,因为空间维度本身太少。这篇论文的巧妙之处在于,它并没有在功率或统计量层面“凑维度”,而是在时频信号层面,通过幅值和相位插值,构造出虚拟麦克风信号。工程上可以把它理解为:假设声场在短时间、窄频带内是平滑变化的,那么在两个麦克风之间的任意位置,都可以估计出一个合理的观测值。
虚拟麦克风的幅值插值并不是简单线性平均,而是通过一种带权的发散度最小化来完成,其结果可以写成下面这种形式,在工程实现中更像是一种对数域或幂域的平滑插值:
相位则采用线性插值,在麦克风间距较小、不发生空间混叠的条件下是成立的。这样一来,系统在算法上就拥有了“多通道观测”,子空间噪声抑制就有了施展空间。
完成噪声抑制后,论文并没有引入复杂的分类器,而是回到了一个非常工程化的判断准则:看剩余信号的能量是否超过阈值。如果超过,就认为发生了异常事件。为了避免短暂脉冲或偶发噪声引发误报,还引入了类似语音检测中的“hang-over”机制,要求异常必须持续一定时间。
实验结果给工程带来的启发
论文的实验场景是一个典型的“多正常声源+单异常声源”的环境:广播音乐、风扇噪声、电视人声作为长期存在的正常声音,而异常则来自不同方向的呼救声。实验中一个很有意思的对比是,当异常声音方向发生变化时,依赖先验方向信息的波束形成方法性能急剧下降,而基于子空间和虚拟麦克风的方法几乎不受影响。
这对工业场景来说非常重要。很多设备的异常声音,并不总是从固定方向传到麦克风,尤其是在工位、箱体或移动部件上。如果算法严重依赖方向先验,一旦现场条件变化,效果就会迅速崩塌。
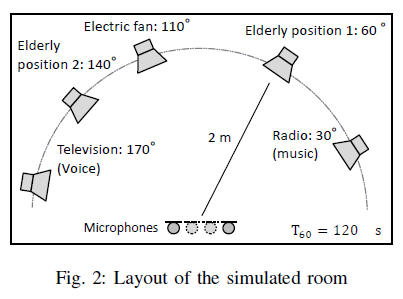
对工业异音检测落地的价值与局限
从工程落地角度看,这篇论文最大的价值在于它证明了一件事:在极其受限的硬件条件下,只要建模思路正确,依然可以获得可用的异常检测性能。对于那些成本、体积、功耗都受限的设备,比如端检工位、小型监测节点、嵌入式终端,这种思路非常有吸引力。
当然,它也有明确的适用边界。虚拟麦克风技术依赖于时频稀疏性,如果现场声源高度重叠、混响极强,插值质量会下降,子空间分离效果也会受到影响。此外,这种方法更适合做“事件级”的异常检测,而不是精细的故障类型识别。
但从工程团队的角度看,这并不是缺点,而是一种清醒的定位。很多时候,我们需要的不是一步到位的“智能诊断”,而是一个稳定、鲁棒、硬件友好的异常触发机制,为后续分析争取时间和窗口。
读完这篇论文,我们最大的感受是,它并没有试图用复杂模型去“压服”现实,而是正视工程约束,在有限条件下把物理、信号处理和实际需求结合得非常克制、也非常聪明。这种思路,对今天做工业声学异常检测的人来说,依然值得反复琢磨。
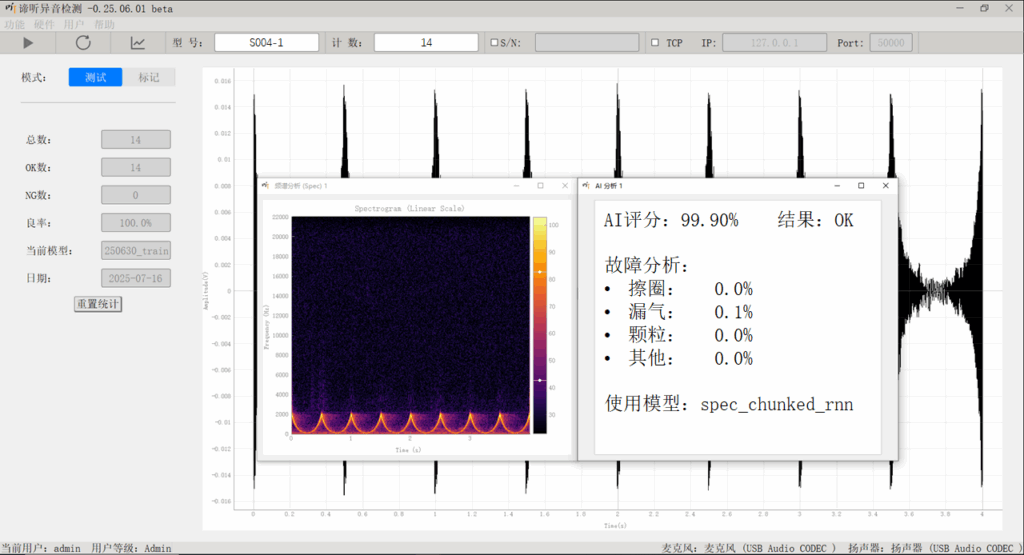
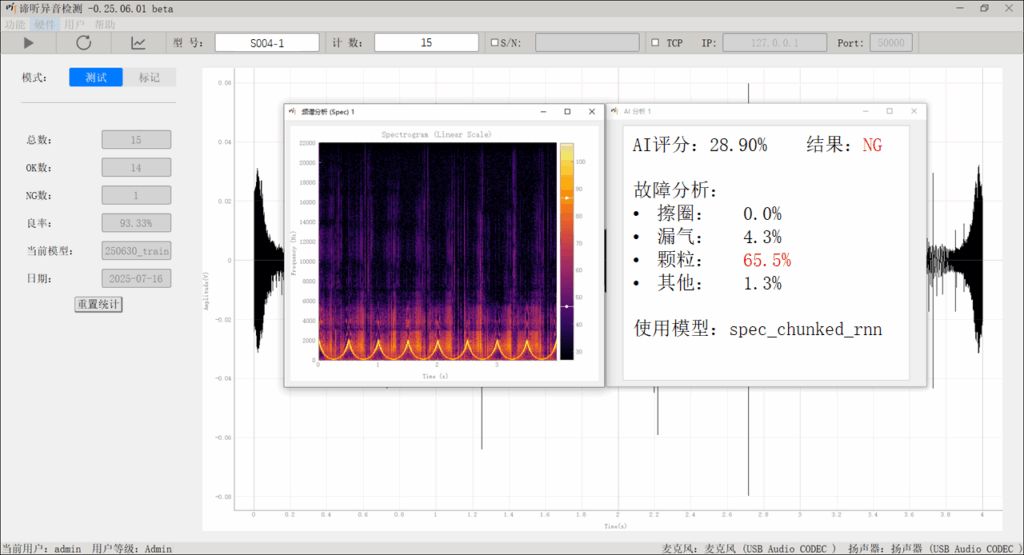
苏州东原电子有限公司推出的 谛听异音检测系统 结合工程化声学感知与深度神经网络,实现复杂工况下异音精准识别与定位,助力设备早期预警、提升品控效率并降低运维成本。它结合了音频信号处理与机器学习技术,能够实时分析声学特性并迅速识别在复杂噪音情况下小电机转动的异响情况。