探索自监督音频模型在广义异常声音检测中的应用
《Exploring Self-Supervised Audio Models for Generalized Anomalous Sound Detection》是由上海交通大学 Bing Han 和 Yanmin Qian 等人在 2025 年 8 月发布,该方案获得了 DCASE 2024 异常声音检测挑战赛的冠军。
1.摘要与引言 (Abstract & Introduction)
1.1 研究背景
机器异常声音检测(Anomalous Sound Detection, ASD)在工业设备监控中扮演着至关重要的角色。然而,在实际应用中,ASD 面临着三大主要挑战:
- 数据稀缺性: 异常样本极难收集,通常只能在无监督框架下仅依靠正常样本进行训练。
- 环境复杂性: 工业环境噪声多变,且不同机器之间的声学特性差异巨大。
- 泛化能力弱: 现有模型难以应对未见过的机器类型(Unseen Machine Types)或工况变化(Domain Shift)。
1.2 现有方法的局限
传统的 ASD 方法主要分为两类:
- 基于重构(Reconstruction-based): 如 AutoEncoder,假设异常样本的重构误差大于正常样本,但在复杂场景下往往失效。
- 基于自监督(Self-supervised-based): 利用元数据(如机器ID)作为伪标签进行分类任务。虽然在 DCASE 挑战赛中表现优于重构方法,但其泛化能力仍然受限,主要归因于缺乏对通用声学特征的学习。
1.3 本文核心贡献
本文提出了一种基于大规模自监督预训练音频模型的 ASD 框架。主要贡献包括:
- 全面评估预训练模型: 首次在 ASD 任务中系统比较了各类语音(Speech)和音频(Audio)预训练模型,发现自监督音频模型(BEATs)效果最佳。
- 全连接多分支 LoRA (Fully-Connected Multi-branch LoRA): 提出了一种新的微调策略,既保留了预训练知识,又避免了过拟合。
- 机器感知组适配器 (Machine-aware Group Adapter): 通过动态分组学习不同机器的差异,显著提升了模型对未见机器类型的泛化能力。
- 双层对比损失 (Dual-Level Contrastive Loss, DLCL): 针对缺失属性标签的场景,设计了动态聚类对比损失。
- SOTA 性能: 该框架在 DCASE 2020 至 2024 的所有基准测试中均取得了最佳结果。
2.核心方法论 (Methodology)
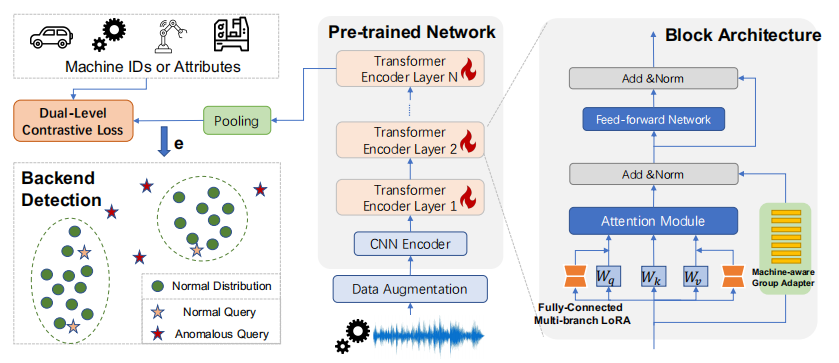
2.1 预训练模型的选择与分析
作者对比了两类模型:
- 语音预训练模型(如 Wav2Vec 2.0, HuBERT): 主要在语音数据集上训练,关注语义信息。实验证明,其在 ASD 任务上提升有限。
- 音频预训练模型(如 AST, BEATs): 在通用音频数据集(如 AudioSet)上训练。其中,BEATs 模型表现最优。
原因分析: BEATs 采用纯自监督学习,不依赖于特定人工标签,学到的特征具有更强的通用性和迁移能力。
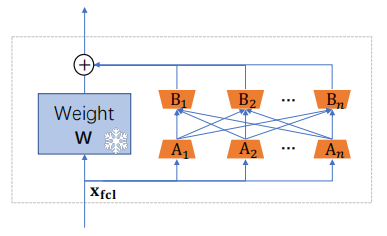
2.2 全连接多分支 LoRA (Fully-Connected Multi-Branch LoRA)
- 结构设计: 在 Transformer 层中并行引入多个 LoRA 分支(Branches),而不是单个分支。
- 全连接交互: 在这些分支之间引入全连接层,允许不同分支的信息进行交互。
- 公式表达:
\[
(W+ \Delta W)x_{fcl} = (W + \sum_{i=1}^{n_l}\sum_{j=1}^{n_l}B_i A_j)x_{fcl}
\\其中, W 是冻结的预训练权重,A 和 B 是可训练的低秩矩阵 [cite: 179]。
\]
优势: 相比全参数微调,该方法有效防止了灾难性遗忘和过拟合。
2.3 机器感知组适配器 (Machine-aware Group Adapter)
- 核心思想: 学习一组“组表示(Group Representations)”,并根据输入声音的特性动态加权组合。
- 工作流程:
- 组决策模块: 计算样本属于各个“组”的概率分布 。
- 加权聚合: 利用概率 p 对可学习向量 G 进行加权求和,得到机器特定表示 xg。
- 特征融合: 将 xg 注入到 Transformer 的注意力模块中。
2.4 双层对比损失 (Dual-Level Contrastive Loss, DLCL)
针对 DCASE 2024 中部分样本缺失属性标签的问题 。
- 实例级对比 (Instance Level): 拉大当前样本与内存库(Memory Bank)中负样本的距离。
- 原型级对比 (Prototype Level): 使用向量量化 (Vector Quantizer) 进行在线聚类,未标记样本自动寻找最近的量化中心 。
- 总损失函数:L=LAAM+λLDLCL
3.实验设置 (Experiment Setup)
- 数据集: 覆盖 DCASE 2020 至 2024 所有挑战赛数据集,涵盖了从基础检测到域偏移、未见机器泛化等多种场景。
- 评估指标: 使用 AUC (Area Under the ROC Curve) 和 pAUC (partial-AUC, p=0.1) 的调和平均数。
- 后端检测器: 统一使用 K-Nearest Neighbors (KNN)。针对域偏移问题,采用源域和目标域双 KNN 评分策略。
4.实验结果与分析 (Results and Analysis)
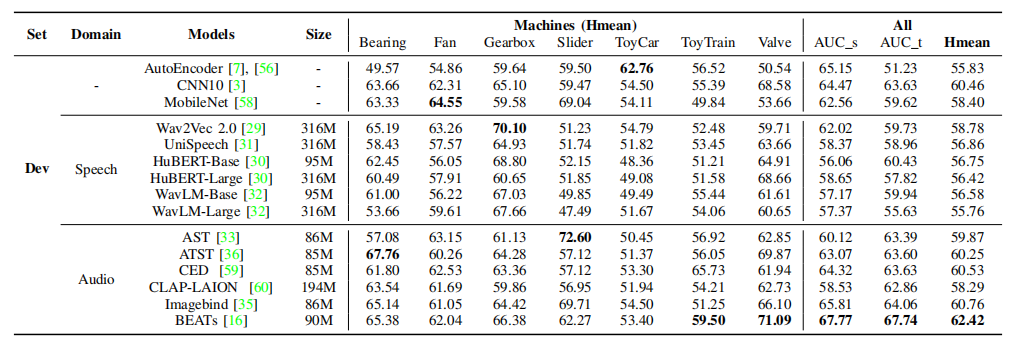
4.1 预训练模型的横向对比
- BEATs 优势显著: 在 DCASE 2024 开发集上,BEATs 显著优于 AST、CED、CLAP 以及所有语音预训练模型。
- 预训练的必要性: 去除预训练权重(随机初始化)后,BEATs 的性能从 ~63% 大幅下降至 ~58%,证明性能提升源于预训练知识 。
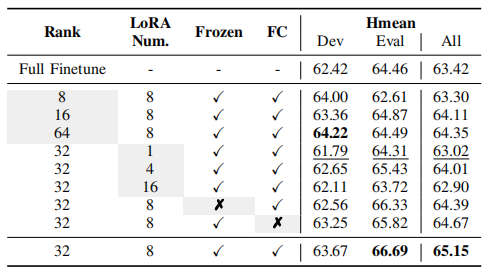
4.2 LoRA 的消融实验
- 微调策略: 冻结参数并使用 LoRA 微调的效果优于全参数微调,特别是在未见机器的评估集上,证明 LoRA 有效提升了泛化性。
- 分支数量: 增加分支数量(如 8 个分支)并引入全连接层,比标准单分支 LoRA 性能更好。
4.3 综合基准测试结果 (DCASE 2020-2024)
该框架在所有年份的数据集上均击败了之前的 SOTA 方法:
- DCASE 2020: 均值 93.05% (前 SOTA: 89.35%)。
- DCASE 2021 (域偏移): 均值 71.17% (前 SOTA: 62.31%)。
- DCASE 2022 (域泛化): 均值 66.63% (前 SOTA: 63.27%)。
- DCASE 2023 (未见机器): 均值 68.65% (前 SOTA: 67.54%)。
- DCASE 2024 (未见机器 + 缺失标签): 均值 65.50%,大幅领先未基于预训练模型的方案。
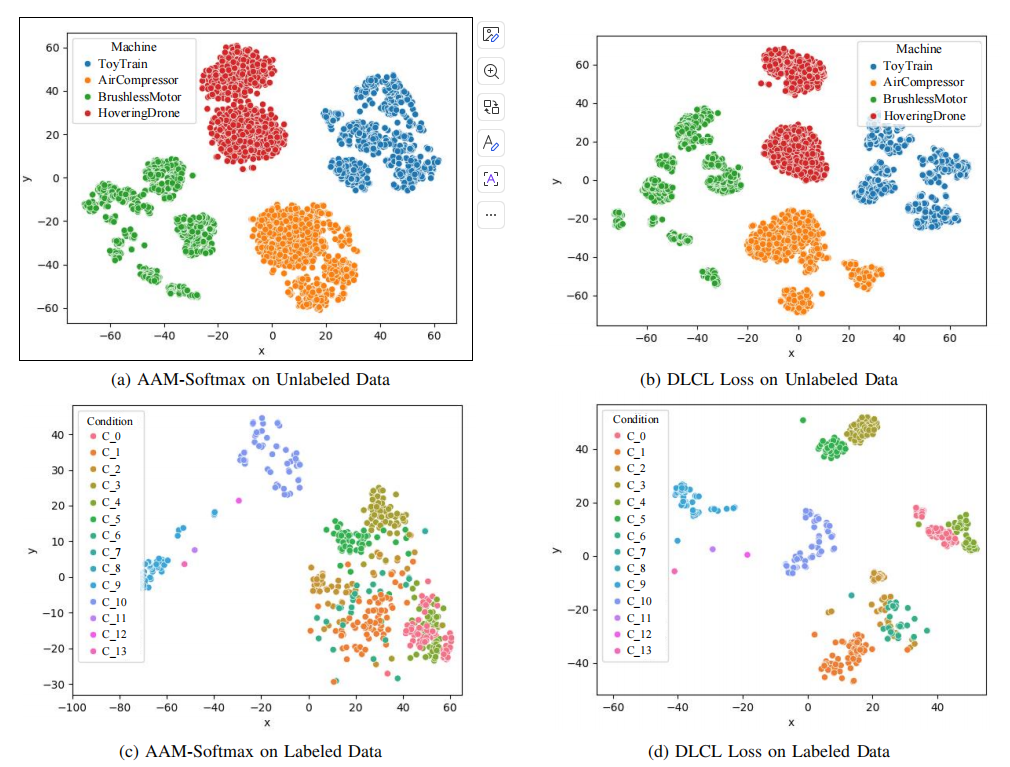
4.4 可视化分析
- 组适配器: 可视化显示不同机器类型激活了不同的适配器权重,证明模型学习到了机器特定的特征模式。
- DLCL 聚类: 使用 DLCL 后,即使没有标签,来自同一机器的样本在特征空间中也能紧密聚类 。
5.结论 (Conclusion)
本研究确立了“预训练大模型 (BEATs) + 高效适配v器微调 (LoRA & Group Adapter)” 的 ASD 新范式。通过利用大规模跨域音频特征和精心设计的适应模块,该框架成功解决了工业异常检测中数据稀缺和泛化难的问题,并在 DCASE 2024 挑战赛中夺得冠军 。
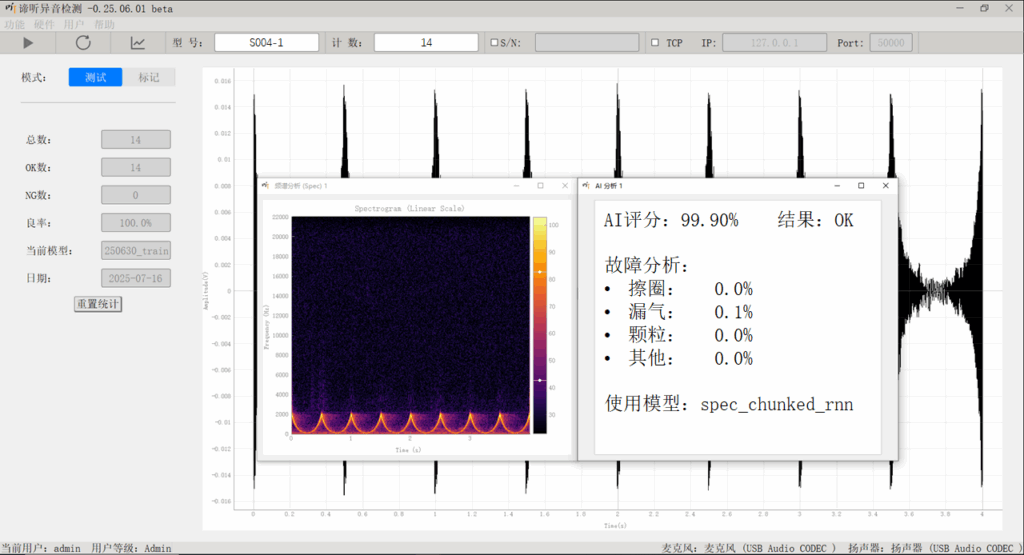
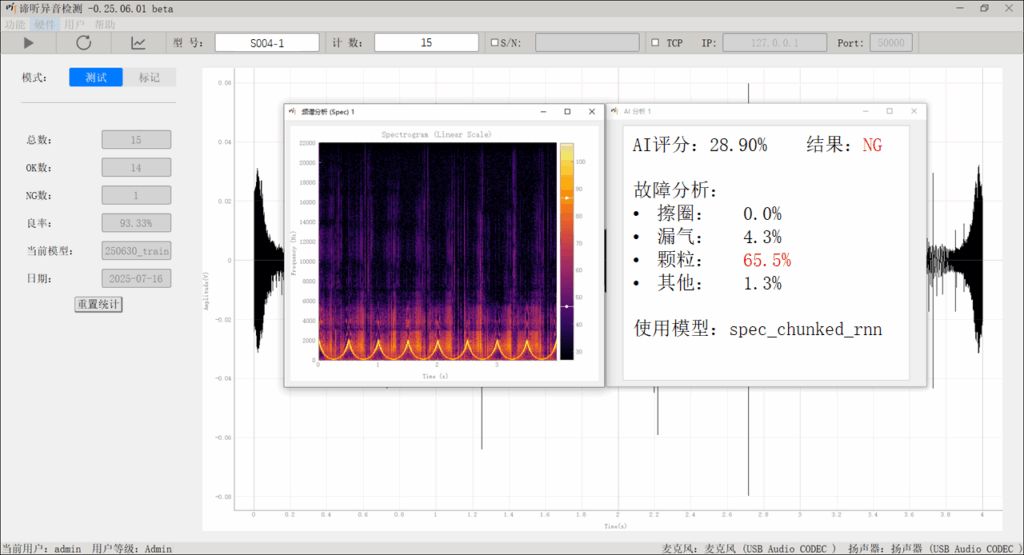
苏州东原电子有限公司推出的 谛听异音检测系统 通过采集大量数据进行深度神经网络学习,构建出先进的机器听觉模型,实现了物理声学和主观听感的统一。通过实时分析声音特性,快速定位问题所在,帮助企业在提升品控效率的同时降低运营成本,并确保产品始终维持高品质输出。