如果 AI 也会“撒谎”:如何让工业异音检测既准又诚实?
本文深度解读 2026 年 1 月由 Mila-Quebec 人工智能研究所发表的重磅论文:Toward Faithful Explanations in Acoustic Anomaly Detection。
想象一下这样的场景:工厂里的老师傅听到机器发出异响,能立刻指出是“轴承磨损”还是“叶片断裂”。而当我们试图用 AI 替代老师傅时,虽然 AI 也能报警说“机器坏了”,但在被问到“坏在哪”时,它却经常指鹿为马,盯着一段完全正常的背景噪音说这是故障原因。
这就是工业 AI 面临的最大信任危机:模型的高准确率(AUC)并不代表它真的“懂”故障,它可能只是蒙对了,或者利用了虚假的关联特征。
为了解决这个问题,这篇论文提出了一套基于 Masked Autoencoder (MAE) 的新方案,并设计了一套“测谎仪”(Faithfulness Metric),用来验证 AI 的解释是否忠实于它的决策逻辑。简而言之,这项研究宁愿牺牲一点点检测精度,也要换取 AI “不说谎”的能力,这对于高风险的工业应用至关重要 。
1、核心痛点:传统的自动编码器为什么“不可信”?
在无监督异常检测领域,自动编码器(Autoencoder, AE)是绝对的主流。它的逻辑很简单:只用正常数据训练,如果遇到异常数据,重构误差(Reconstruction Error)就会变大。
但在实际的声学场景(如木材加工厂的刨床监控)中,传统的 AE 有两个致命弱点:
- “死记硬背”导致漏检:AE 有时过于强大,能够完美重构出它从未见过的异常声音,导致误差很小,无法触发报警。
- 解释错位:当我们试图用热力图(如 Saliency Map)去解释“为什么报警”时,AE 经常会高亮显示一些无关紧要的频率区域,甚至是背景噪声,而不是真正的故障声音 。
解决方案? 给模型戴上眼罩——使用 Masked Autoencoder (MAE)。
2、核心方法:MAE 的“填空题”训练法
2.1 像做完形填空一样学习声音
与传统 AE 试图重构整张频谱图不同,MAE 在训练时会随机遮挡掉一部分输入(Masking),强迫模型根据剩余的上下文信息去“猜”被遮挡的部分长什么样。
- 输入处理:将 10 秒的工业音频转换为 的梅尔频谱图(Mel Spectrogram)。
- 训练策略:
·掩码(Masking):随机遮挡频谱图的一部分。
·损失函数:仅计算被掩盖区域的重构误差(MSE)。
·核心逻辑:模型不能再通过简单的“复制粘贴”来欺骗 Loss 函数,它必须真正理解声音的结构和纹理(比如木板通过刨床时的特定频率纹理),才能填补空白。
- 最佳参数:实验发现,30% 的掩码率配合 的 Patch 大小效果最好。掩码率过高(如 90%)会导致信息丢失,过低则退化回普通 AE。
注意:在推理(Inference)阶段,模型接收的是完整的、未掩码的频谱图,通过计算输入与输出的全局差异来检测异常 。
2.2 六种解释方法的“大乱斗”
为了看看谁能最准确地指出故障,研究者使用了六种不同的归因(Attribution)方法来生成“解释图” :
- Error Map(误差图):最直接的方法,哪里重构得差,哪里就是异常。
- Saliency Map:计算 Loss 对输入像素的梯度。
- Integrated Gradients (IG):积分梯度法,理论上更严谨。
- SmoothGrad:加噪声求平均梯度,去噪效果好。
- GradSHAP:结合 SHAP 值的梯度近似。
- Grad-CAM:利用卷积层激活图,分辨率较低。
3、评估体系:如何判断 AI 是否在“胡说八道”?
这是论文最精彩的部分。通常我们只看 AUC(检测准不准),但本文提出了两个维度来评估解释的质量:“像不像人” 和 “是不是真的”。
3.1 F-score:跟专家比,你指得准吗?
- 基准:专家人工标注了 46 个包含断板(Broken Board)等明显故障的测试样本,精确到秒。
- 计算:将 AI 生成的 2D 解释图压缩成时间轴上的 1D 信号。如果 AI 认为异常的高峰区域(Peak)落在了专家标注的时间段内,就算“抓住了”;否则就是误报或漏报。
- 意义:这个指标衡量了 AI 的直觉是否符合人类专家的听感。
3.2 Faithfulness(忠实度):你真的是因为这里才报警的吗?
这是一个量化“诚实度”的创新指标。
- 逻辑:如果 AI 在解释图中高亮了一个区域,声称“这里是异常”,那么当我们把这个区域“修好”(替换成模型认为正常的重构值)后,模型的报警分数(重构误差)应该会大幅下降。
- 公式:
- 解读:
如果 很高:说明把这个区域修好后,模型觉得一切正常了。证明模型确实是依据这个区域做出的判断(解释是忠实的)。
如果 很低:说明修了这个区域,模型依然觉得有问题。证明模型刚才的高亮是在“撒谎”或指错了地方。
4、实验结果:信任比完美更重要
实验在真实的木材厂刨床数据上进行,结果非常耐人寻味。
4.1 检测性能 vs. 可解释性
- AUC(检测准确率):
·标准 AE:0.885
·MAE:0.864
·结论:MAE 的硬指标稍微弱了一点点(约 2% 的下降)。 - F-score(定位精准度):
·MAE 在几乎所有解释方法上都完胜 AE。
·特别是在 Saliency Map 方法上,MAE 在 98th 百分位阈值下达到了 0.63 的高分,而 AE 只有 0.45 左右。这意味着 MAE 能更精准地在时间轴上抓住故障发生的瞬间 。 - Faithfulness(忠实度):
·MAE 的解释图(尤其是 Error Map)展现出了极高的忠实度。这说明 MAE 的报警逻辑非常线性、直接:它报警的地方,就是它真正没法重构(认为是异常)的地方。
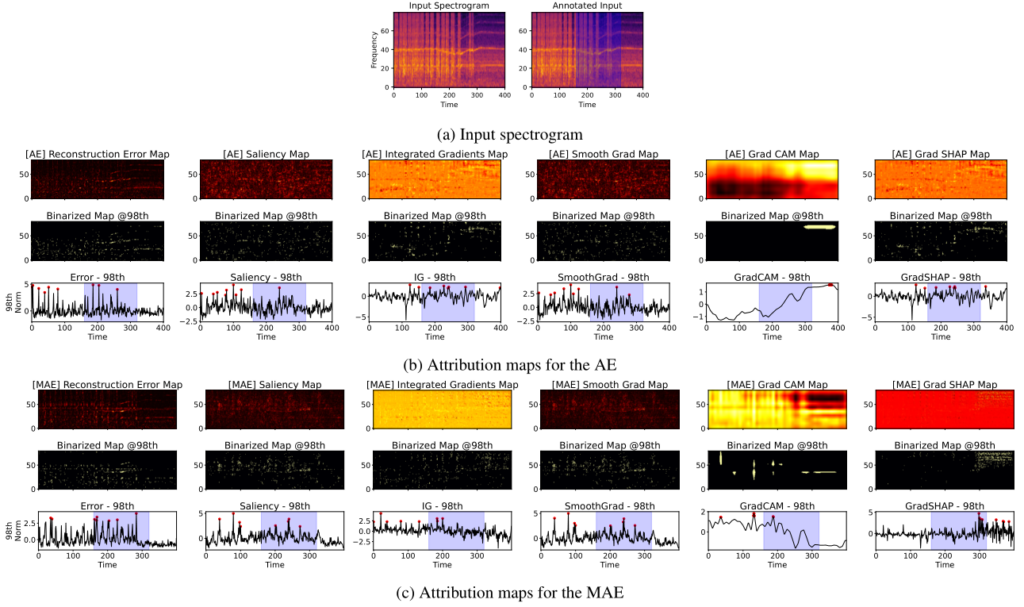
4.2 可视化对比(有图有真相)
参考论文中的 Figure 3(断板故障案例):
- AE 的解释:像是一团散沙,东一块西一块,甚至高亮了很多背景噪声区域。
- MAE 的解释:生成的 Error Map 非常清晰、结构化,精准地勾勒出了断板声音在频谱图上的纹理(非水平的瞬态线条),且完美覆盖了人工标注的区域。
5、总结与启示
这篇论文给工业 AI 开发者(也许就是你!)带来了三个重要启示:
- 不要只迷信 AUC:在工业现场,一个 AUC 0.99 但无法解释的黑盒,远不如一个 AUC 0.95 但能告诉操作员“第 3 秒有断裂声”的模型有价值。
- MAE 是提升解释性的神器:通过简单的 Masking 训练策略,可以让模型从“死记硬背”转向“理解语义”,从而生成更聚焦、更忠实的异常热力图。
- 重构误差图(Error Map)最靠谱:在 MAE 架构下,最简单直接的 Pixel-wise Error Map 反而是忠实度最高、定位最准的解释工具,比复杂的梯度方法(如 Grad-CAM)更实用。
一句话总结:如果你希望你的 AI 模型不仅能当“报警器”,还能当“诊断师”,那么请尝试给它戴上眼罩(MAE),让它学会真正地“听懂”声音。
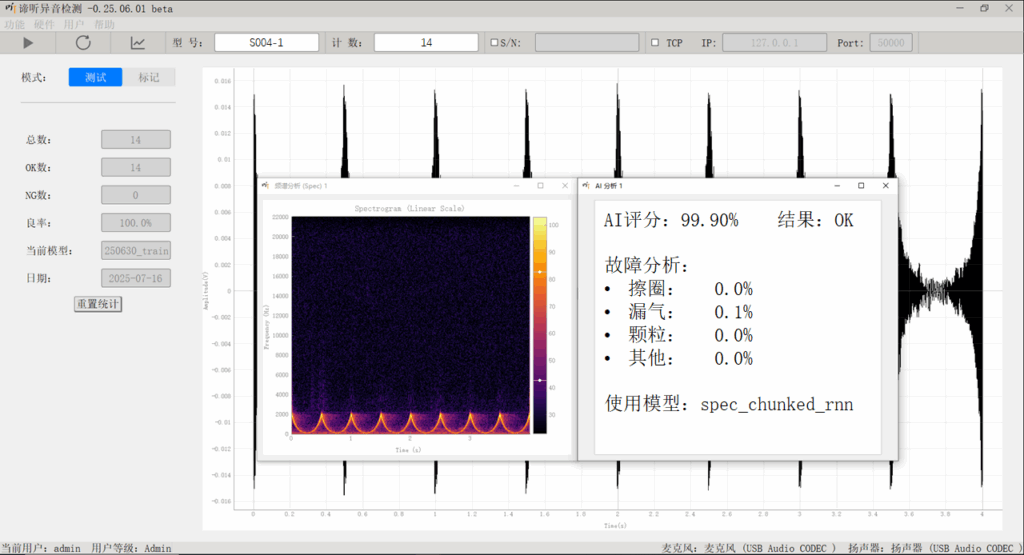
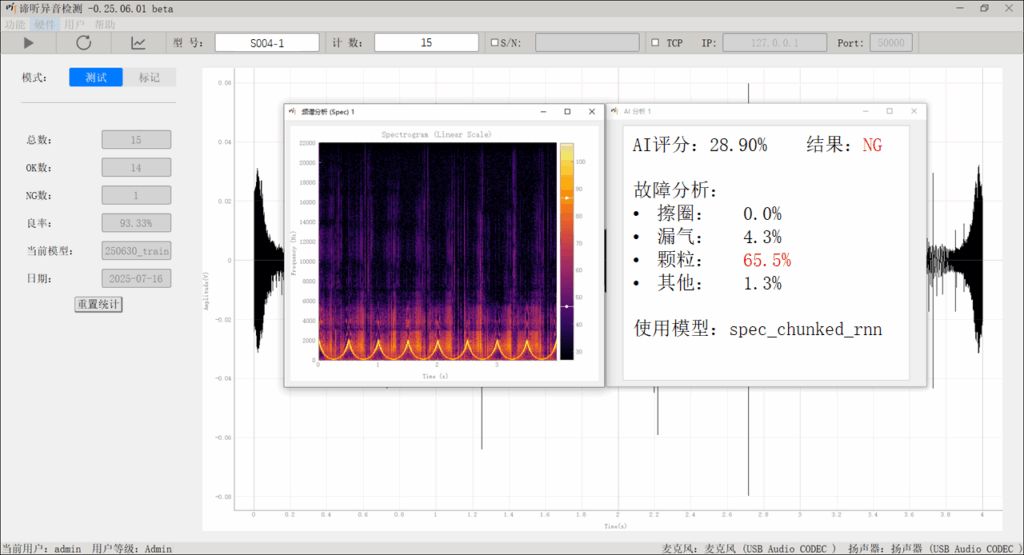
随着 AI 异音检测在工业质检中的广泛应用,检测结果是否可解释、是否可信正成为关键问题。苏州东原电子研发的的谛听异音识别软件 将这一研究思想融入工业实践,通过更合理的模型训练与异常归因机制,使模型高亮的时间与频率区域真实对应影响判定的声学特征。该方案在扬声器、小电机等复杂场景中,可更精准定位异响源,降低误报率,为工业异音检测提供可追溯、可验证的智能分析能力。