低算力声学节点下的异音检测方法:面向小电机与交通噪声的异常声音识别研究
翻译自《Detection of Anomalous Noise Events on Low-Capacity Acoustic Nodes for Dynamic Road Traffic Noise Mapping within an Hybrid WASN》作者:Rosa Ma Alsina-Pagès , Francesc Alías, Joan Claudi Socoró and Ferran Orga 2018.4.20
在工业现场从事声学、振动或 NVH 检测的人,几乎都会遇到这样一种情况:测试流程是规范的,传感器选型和算法方案看起来也足够专业,但最终输出的结果却总让人心里没底。问题往往并不在于信号有没有采到,而在于采到的声音里,但在复杂环境下,这些关键声音很容易被背景噪声淹没。苏州东原电子的👉AI异音异响检测系统👈,针对低算力声学节点优化算法,即便在多设备同时运作、环境噪声复杂的产线,也能快速、精准地捕捉微弱异常声信号。无需依赖人工听音,系统即可实现实时异常报警与数据记录,帮助企业提前发现问题、降低维修成本、提升生产线稳定性与产品品质。
这种现象在城市噪声监测中表现得尤为典型。理论上我们希望评估的是道路交通本身的噪声水平,但实际采集到的信号中,往往同时包含警笛、鸣笛、人群说话、音乐、施工声,甚至飞机或轨道交通的声音。这些声音并不是系统的目标,却很容易在短时间内主导声能量。如果不加区分地参与等效声级计算,最终得到的噪声评估结果就会被明显放大,从而失去原本用于管理和决策的工程价值。
类似的问题在工业场景中同样普遍存在。测试电机时混入人声和背景设备噪声,检测滑轨或轴承时叠加偶发的敲击声,风扇或减速机构测试中混入环境冲击声,产线异音检测中受到相邻工位作业的干扰。这些声音并不代表设备状态异常,但却足以触发系统误判。久而久之,工程人员对系统输出的信任度会不断下降,而这往往比单次误判本身更致命。
也正因为如此,异常声音检测在工程系统中并不是一个可有可无的功能,而是决定整套声学或振动检测系统是否可信的基础能力。
在过去几年里,异常声音检测的主流思路大多来自机器听觉和机器学习领域。通过提取 MFCC 等特征,再配合统计模型或神经网络,对声音进行分类识别。在实验室环境或服务器端,这类方法往往可以取得不错的指标表现,也在技术展示中显得十分先进。但当系统真正走向工程现场时,这些方法的问题很快就会暴露出来。
首先是算力和功耗的现实约束。大量声学或振动节点部署在边缘位置,硬件资源有限,依赖电池或太阳能供电,需要长期连续运行。在这样的条件下,复杂特征提取和模型推理的计算成本会被无限放大。其次是工程复杂度和可维护性的问题。模型需要训练、需要更新、需要重新标定,一旦现场环境发生变化,系统行为就很难解释,这在长期运行的工业系统中意味着更高的维护成本和更大的不确定性。
在这样的背景下,我们在阅读这篇研究时,最深的感受并不是算法有多新,而是它提出了一个非常工程化的问题视角:异常声音和目标声音,是否在最基础的频谱能量结构上就已经存在稳定差异。如果这种差异本身就足够明显,那么是否真的有必要引入复杂的模型?
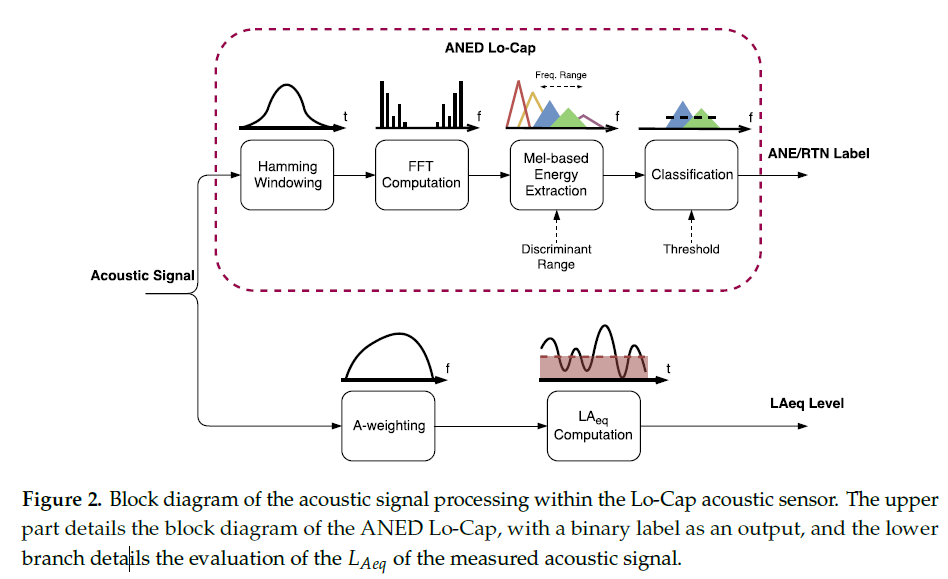
基于这一思路,文中给出的方案在特征层面做了非常克制的取舍。完整的 MFCC 流程被舍弃,只保留了 Mel 频带能量这一层信息。Mel 滤波本身符合人耳对频率的感知特性,同时计算量远低于倒谱分析,这一点对于嵌入式和低功耗平台来说非常关键。
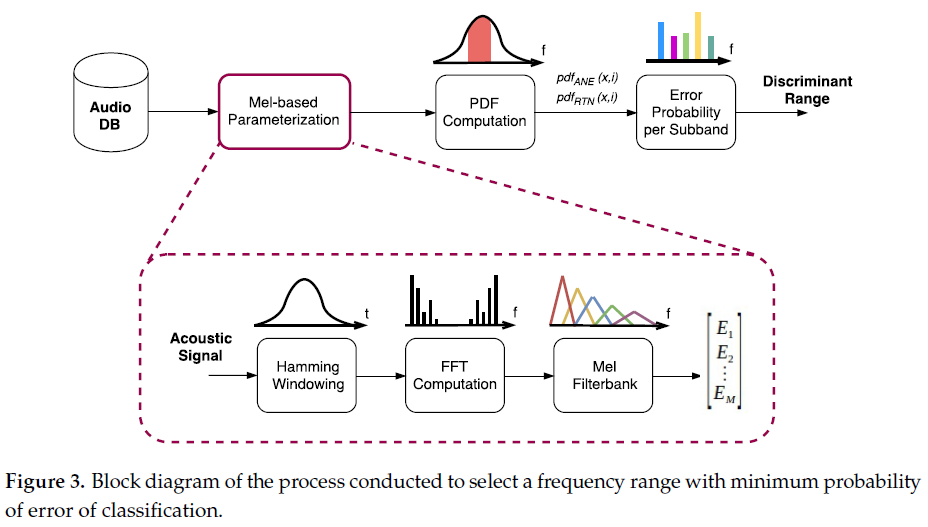
更重要的一步在于频段选择。方案并没有假设所有频率都同样重要,而是利用真实环境下的大量数据,对每一个 Mel 频带中目标声音和异常声音的能量分布进行统计分析。通过比较不同频带上的重叠程度,找出真正有区分力的频谱区域。分析结果表明,在不同应用环境下,有效频段并不相同。例如在城市环境中,低频段往往更有利于区分道路交通噪声与异常声;而在背景更为安静、声源类型相对单一的场景中,中频段反而更具判别能力。
这一结论对工程实现具有非常直接的指导意义。它意味着异常检测不再需要对全频谱进行平均计算,而是可以把有限的计算资源集中在最关键的频率范围内。这种思路对于端侧算法尤为友好。
在实际实现中,算法结构被进一步简化。系统只对选定的几个 Mel 频带能量进行求和,并与一个事先标定好的阈值进行比较。当能量超过阈值时,认为当前声音更可能属于异常事件;否则,则认为属于目标声音。这一判据在工程上可以非常直观地描述为:
判定规则如下:
- 当 E > γ,判定为异常声音;
- 当 E ≤ γ,判定为目标声音。
其中
- Ei 为第 i 个频带内的能量,
- Ω 为选定的频段集合,
- γ 为能量判定阈值。
这种方法在算法层面看起来并不复杂,但在工程上却有一个极其重要的优势,那就是系统行为完全可解释。工程人员可以清楚地知道系统依据哪些频段、哪些能量变化做出判断,也可以根据现场环境变化重新调整频段或阈值,而不需要重新训练模型。
在系统运行过程中,异常声音检测模块与等效声级或状态指标计算并行工作。当某一帧被判定为异常声音时,这一帧的数据就不会被计入长期统计结果,从而避免偶发事件对整体评估造成干扰。这一点在城市噪声评估和工业状态监测中都具有非常直接的工程价值。
从实验和评估结果来看,这种极简方案的计算量大约只有传统高算力方案的六分之一,完全可以在低功耗 ARM 平台上实时运行。在复杂城市环境中,其异常检测效果已经能够满足工程使用需求。虽然它并不追求极致精度,但在边缘节点和长期运行场景下,这样的取舍是合理且务实的。
更重要的是,这种方法在工程上是可控的。它不依赖黑盒模型,也不会因为环境变化而突然失效,系统行为始终处在工程人员的理解范围之内。这一点在工业应用中,往往比单纯的精度指标更重要。
虽然这项研究最初面向的是城市噪声监测,但其中的思想对工业异音检测和设备状态监测同样具有很强的启发意义。在很多工业场景中,端侧设备并不需要一个足够聪明的算法,而是需要一个算得动、跑得久、行为稳定的判断机制。当我们把关注点从算法复杂度转向系统可持续运行能力时,往往会发现,问题的本质差异其实早已体现在最基础的物理特征之中。
这篇工作的价值,并不在于提出了一种全新的算法形式,而在于它展示了一种成熟而克制的工程思维:在资源受限的前提下,用最小的代价解决最关键的问题。这种思路,对于正在推动工业声学、振动监测和异音检测真正落地的团队来说,往往比任何单一算法都更值得借鉴。
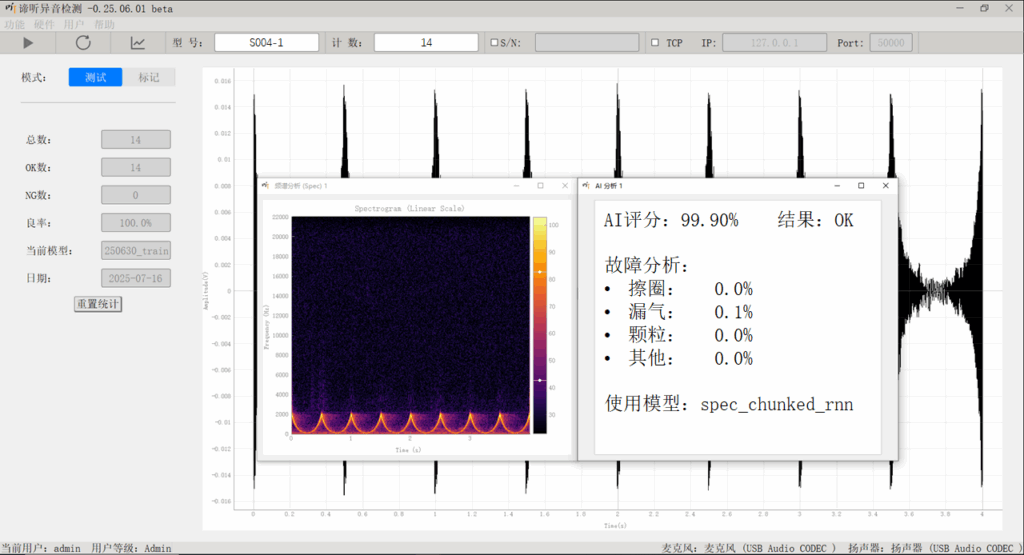
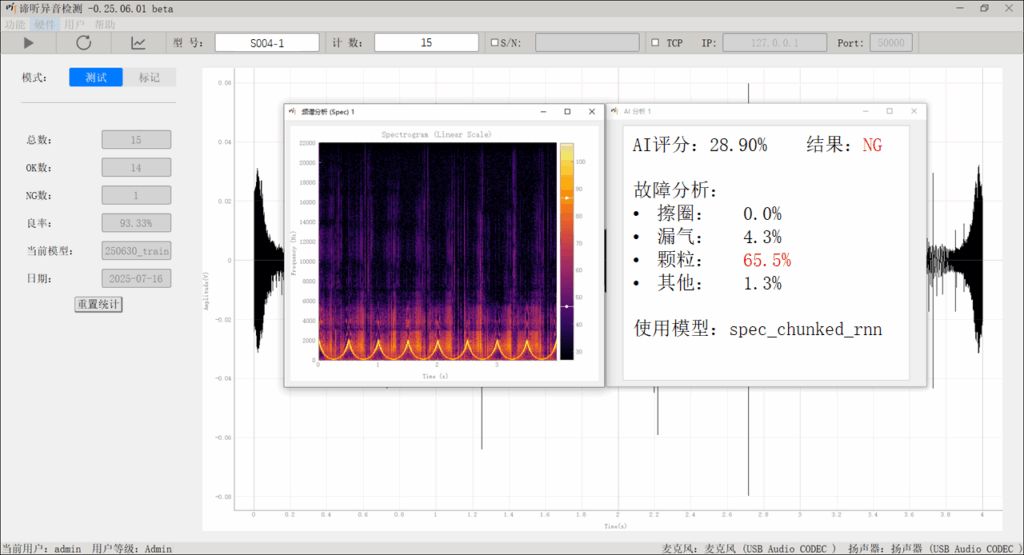
苏州东原电子有限公司推出的 谛听异音检测系统 融合音频分析与深度学习,实现复杂工况中设备异响的精准感知与定位,支持早期故障预警,提升质量管控效率并有效降低运维成本。