为什么AI异音检测在环境变化时容易误报?一条简单规则提升检测鲁棒性
工厂里有一类质检工作靠”听”:电机运转有没用异音?经验丰富的工人能凭耳朵判断,但 AI 来进行异音检测时,有个棘手的前提——你只有正常声音的数据,没人会故意把机器弄坏给你当教材。所以只能学”正常长什么样”,然后把偏离正常的标记为异常。
这个思路本身没问题,问题出在环境一变,同一台没坏的机器,测量和计算得到的声音特征”看起来”也不正常了。Aalborg University 和三菱电机研究院(MERL)的一篇新论文追查了这个现象背后一个被忽略的原因,顺便给了一个不需要训练的修补方案。
背景:距离检测 + 局部归一化
异常声音检测的基本流程是:把几秒钟的机器声音通过神经网络编码成高维嵌入向量,在向量空间里量新样本和已知正常样本之间的距离——距离远就可能异常。
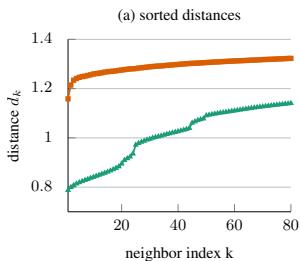
图 1(a):排序后的邻居距离曲线。 横轴是按距离排序后的邻居编号 k,纵轴是距离。源域(绿色)距离平稳上升,目标域(橙色)在前几个邻居后出现剧烈跳变。
但同一台机器换了录音设备、换了背景噪声、甚至只是温度变了,声音分布就会漂移——这就是域偏移 [1]。机器本身没坏,但在嵌入空间里,不同运行条件下的正常样本会各自抱团,形成分散的聚类。
为了应对这个问题,已有的做法是局部密度归一化(LDN)[2] [3]:把异常分数除以局部邻域的平均距离,使得密集区和稀疏区的分数可以横向比较。
局部密度归一化有一个关键参数 K——看几个最近邻来估计局部密度。按直觉 K 越大估计越稳定,但实验结果是 K 从 1 增到 2 性能提升,之后再大就单调下降。大家一直把 K 固定为 1 或 2 [3],虽然管用,但没人能完全解释清楚为什么大 K 不行。
核心发现:性能下降不是因为 K 太大,是因为”越界”了
这篇论文给出的解释很直接:邻域扩大时,邻居可能已经不在同一个聚类里了。
打个比方:你想估自家小区的房价,问隔壁邻居合理,但如果范围扩大到一墙之隔的别墅区,数据就被污染了,虽然别墅区可能比小区其他房子离你更近。
在嵌入空间里同理。同一运行条件的正常样本形成紧凑聚类,K 一旦超出这个聚类的边界,新纳入的邻居来自其他条件的数据——局部密度估计的”局部性”被破坏了。论文把这个现象叫聚类退出(Cluster Exit)。
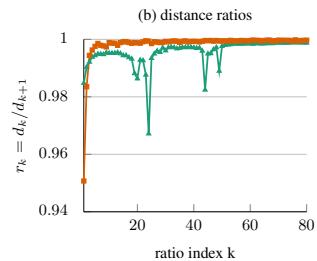
图 1(b):距离比曲线。 每个点是相邻两个邻居距离的比值,接近 1 说明距离平稳增长,急剧下降说明出现距离跳变。目标域(橙色)在很早期就出现了低比值。
从图 1 能看清楚:源域(绿色,训练数据充足)距离平滑增长,邻域扩大到较大 K 也没问题;目标域(橙色,训练数据少)前几个邻居之后距离就断崖式跳升,多看几个邻居就已经”出圈”了。
解决方案:聚类退出检测
既然问题在”越界”,修法也直接:别用固定 K,让每个样本自己决定看多远——在越界之前停下来。
具体做法分三步:
1. 算距离比。 把每个参考样本到所有邻居的距离从近到远排序,算相邻距离的比值
比值接近 1 说明还在同一聚类内,比值突然变小说明出现了距离跳变。
2. 找断点。 在比值序列中找到第一个显著低于整体水平的点(低于所有比值的第 4 百分位数),同时找到全局最小比值的位置,取较早的那个作为停止点。
3. 自适应选 K。 每个参考样本得到自己的邻域大小
有的样本可能有 50 个邻居在同一聚类内,有的可能只有 3 个。对于极度稀疏区域的样本,算法回退到只用 2 个邻居,避免数据不足时的误判。
整个方法纯粹基于统计量,没有可学习参数,也不需要额外调参。现有局部密度归一化系统想用的话,把固定 K 换掉就行。
实验结果
论文在 5 个嵌入模型(Direct-ACT [4]、OpenL3 [5]、BEATs [6]、EAT [7]、Dasheng [8])和 DCASE 2020–2025 共 5 个基准 [9] [10] [11] [12] 上做了评估。
图像结果
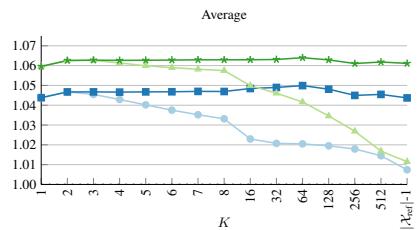
图 2(平均性能):不同方法的性能随 K 变化的趋势。 纵轴为相对于不使用局部密度归一化时的性能比。浅绿色线(局部密度归一化)随 K 增大显著下降;深蓝色线(局部密度归一化+聚类退出检测)在 K=16~512 的范围内保持稳定。
核心信息:没有 聚类退出检测 时性能在 K=2 达峰值然后一路下滑;加了 聚类退出检测 后曲线被”拉平”了,最优 K 值从 1–2 转移到 16–64,对 K 的选择不再敏感。
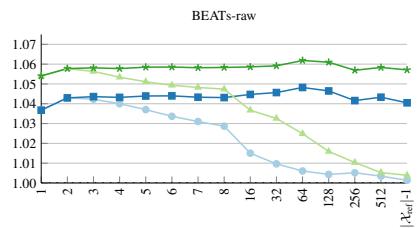
BEATs 模型: 原始局部密度归一化在 K>8 后急剧下降;+聚类退出检测 始终保持高位。
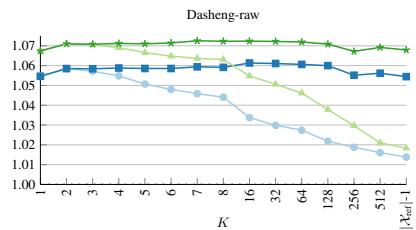
Dasheng 模型: 趋势一致,聚类退出检测 消除了对 K 值的敏感性。
量化数据
表中 VarMin [13] 是一种通过最小化归一化分数方差来进一步稳定 局部密度归一化 的方法。
| 对比维度 | 数据 |
|---|---|
| 总体平均增益 | +0.19%(不含 VarMin)/ +0.07%(含 VarMin) |
| 单划分最大增益 | +1.39%(DCASE2023,不含 VarMin) |
| 受益模型比例 | DCASE2022–2025 上至少 4/5 的模型获得提升 |
| DCASE2020 | 几乎无增益 |
绝对数字不大,但该领域的评估指标(AUC 调和均值)本身就在高基线上,0.3% 的稳定提升已经不小。而且这是跨 5 个模型 × 5 个数据集的系统性结果,不是某个特定场景下的偶然。
DCASE2020 无增益这件事反而印证了论文的理论。由于该数据集几乎没有域偏移,数据分布均匀,不存在聚类退出问题,聚类退出检测 自然没有发挥空间。
总结
论文最大的贡献其实不是 聚类退出检测 这个算法,而是把”K 增大为什么性能会下降”这个问题提供了一个新思路。之前大家只知道 K 要取小值,但不知道为什么。”越界”这个解释一说出来,后续改进的方向就清晰了,诊断本身比开的药方更有价值。
方案也足够轻,只用距离比和一个百分位数阈值,现有局部密度归一化系统换掉固定 K 就行,推理成本不增加(局部密度可以预计算)。另外虽然论文做的是异常声音检测,但”邻域扩展时检测聚类退出以保持局部性”这个思路,在基于 KNN 的异常检测和密度估计任务里大概率也能用。
苏州东原电子有限公司依托多年声学测试与算法研发经验,组建专业声学与AI技术团队,具备从传感采集、信号处理到模型优化的完整技术能力。自主研发的“谛听异音检测系统”融合机器听觉与工程化算法,可有效实现电机异音异响检测与噪声识别分析,提升检测稳定性与准确率,助力企业实现高效率、高一致性的智能化质量管控。
论文信息
- 标题: Mind the Gap: Detecting Cluster Exits for Robust Local Density-Based Score Normalization in Anomalous Sound Detection
- 作者: Kevin Wilkinghoff, Gordon Wichern, Jonathan Le Roux, Zheng-Hua Tan
- 机构: Aalborg University / Pioneer Centre for AI / MERL
参考文献
[1]: K. Wilkinghoff, T. Fujimura, K. Imoto, J. Le Roux, Z.-H. Tan, and T. Toda, “Handling domain shifts for anomalous sound detection: A review of DCASE-related work,” in Proc. DCASE, 2025.
[2]: K. Wilkinghoff, H. Yang, J. Ebbers, F. G. Germain, G. Wichern, and J. Le Roux, “Keeping the balance: Anomaly score calculation for domain generalization,” in Proc. ICASSP, 2025.
[3]: K. Wilkinghoff, H. Yang, J. Ebbers, F. G. Germain, G. Wichern, and J. Le Roux, “Local density-based anomaly score normalization for domain generalization,” IEEE Trans. Audio, Speech, Lang. Process., vol. 33, 2025.
[4]: K. Wilkinghoff, “Self-supervised learning for anomalous sound detection,” in Proc. ICASSP, 2024.
[5]: A. Cramer, H. Wu, J. Salamon, and J. P. Bello, “Look, listen, and learn more: Design choices for deep audio embeddings,” in Proc. ICASSP, 2019.
[6]: S. Chen et al., “BEATs: Audio pre-training with acoustic tokenizers,” in Proc. ICML, 2023.
[7]: W. Chen, Y. Liang, Z. Ma, Z. Zheng, and X. Chen, “EAT: Self-supervised pre-training with efficient audio transformer,” in Proc. IJCAI, 2024.
[8]: H. Dinkel, Z. Yan, Y. Wang, J. Zhang, Y. Wang, and B. Wang, “Scaling up masked audio encoder learning for general audio classification,” in Proc. Interspeech, 2024.
[9]: Y. Koizumi et al., “Description and discussion on DCASE2020 Challenge Task 2: Unsupervised anomalous sound detection for machine condition monitoring,” in Proc. DCASE, 2020.
[10]: K. Dohi et al., “Description and discussion on DCASE 2022 Challenge Task 2: Unsupervised anomalous sound detection for machine condition monitoring applying domain generalization techniques,” in Proc. DCASE, 2022.
[11]: K. Dohi et al., “Description and discussion on DCASE 2023 Challenge Task 2: First-shot unsupervised anomalous sound detection for machine condition monitoring,” in Proc. DCASE, 2023.
[12]: T. Nishida et al., “Description and discussion on DCASE 2024 Challenge Task 2: First-shot unsupervised anomalous sound detection for machine condition monitoring,” in Proc. DCASE, 2024.
[13]: M. Matsumoto, T. Fujimura, W. Huang, and T. Toda, “Adjusting bias in anomaly scores via variance minimization for domain-generalized discriminative anomalous sound detection,” in Proc. DCASE, 2025.