基于AI的机器听觉系统
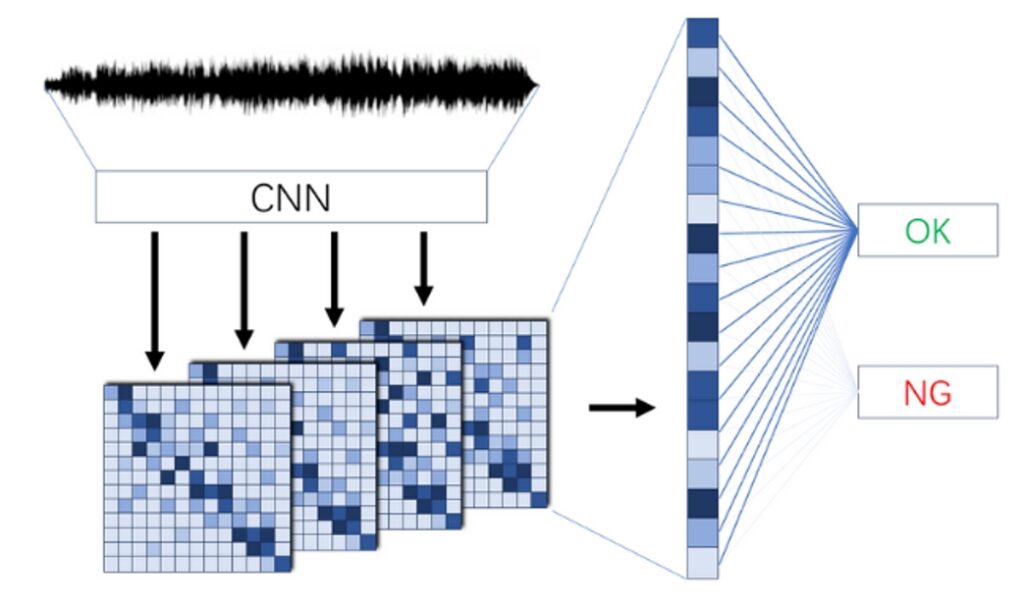
谛听异音检测是一种利用深度学习和信号处理技术模拟和增强人类听觉能力,以实现高精度声音识别、分类和分析的智能系统。

谛听异音检测系统允许您开发测试或修改现有的测试,所有测试步骤均可模块化地添加到您的测试流程中。一个测试流程是多步骤的,每一步执行特定的任务。一种非常简单的测试流程可能具有以下结构:
有许多其他类型的步骤可用,包括后处理、打印、统计等。这使得用户能够轻松地创建复杂的测试序列,并将其应用于DUT,从而获得所需的测量结果和分析数据。
基本功能
实时采集
音频播放和波形图的实时绘制
扬声器型号管理
音频分析
计算声压级、频率响应、谐波失真
AI模型对扬声器质量进行判断
硬件校准
输入信号校准和输出信号校准,保证音频采集的准确性与一致性
数据管理
数据全生命周期管理,实现数据可追溯,保证数据安全
AI模型定制化训练
通过真实数据训练获得更符合产品实际情况的模型
模型架构优化
根据需求自由配置模型架构,可依据训练结果对模型进行调优
AI预测分析
根据训练好的模型对产品进行评分判定,在展示客观分析数据的同时更符合人耳听音感受
模型管理
模型信息在数据库内加密归档,保证数据安全
软件特点
人工智能信号分析
采用最新的声学深度神经网络架构,进行音频识别与分析,准确率更高,分析速度更快,普适性更广,可扩展性更强。
模块化设计
所有测试步骤均可模块化导入或根据您的需求进行定制。
外部拓展
谛听异音检测系统支持外部命令控制,使用JSON数据格式,使得命令返回信息以便于任何编程语言解析,并可通过该API打开并运行。
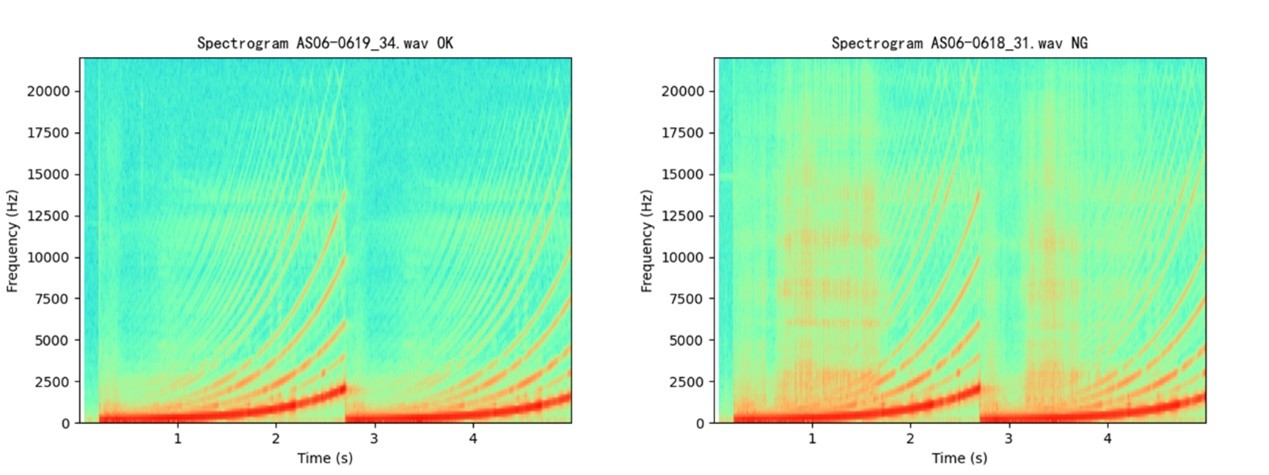
频谱图分析
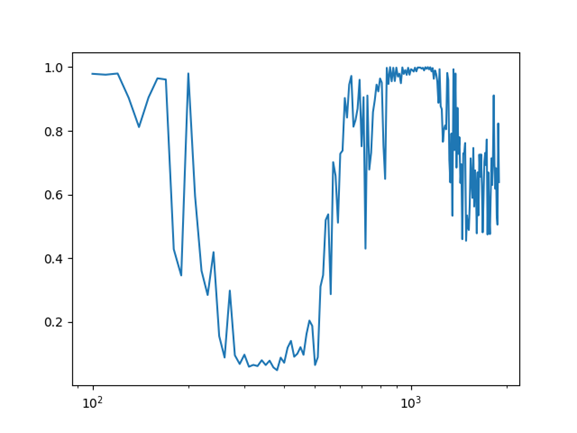
失真分析
数据离散度分析
时频分析
详细的信号分析同时在时域和频域中进行,非常适合用于脉冲响应分析以及检测扬声器中的松散颗粒和摩擦嗡嗡声(Rub & Buzz)。时频分析对于识别数字设备中的瞬态效应(如 VoIP 和蓝牙耳机中的信号丢失)也非常有价值。谛听异音检测系统的时频分析选项包括瀑布图/累积频谱衰减(CSD)、Wigner-Ville 分析、短时傅里叶变换(STFT)和小波分析。
频率响应测量
谛听异音检测系统提供多种选项,用于在各种应用中测量频率响应。简单的正弦扫频被用于测试基本的传感器,通过高精度滤波器分析信号,提供最佳的信噪比。对于更复杂的场景,谛听异音检测系统的实时分析仪可以使用宽带激励信号(如语音)测量频率响应。传递函数分析允许直接比较输入与输出,非常适用于电子产品的测试。需要在开放空间而非消声室中测试的客户可以利用谛听异音检测系统的高级时间选择响应模块,进行模拟自由场测量。
失真分析
Add unique list items while keeping a consistent没有单一的失真测量方法能够全面表征设备或检测所有可能的制造缺陷,因此谛听异音检测系统集成了一整套失真分析算法,以满足各种需求。这些算法涵盖了从传统测量方法(如总谐波失真(THD)、摩擦和嗡嗡声(Rub & Buzz)、互调失真)到先进的感知失真指标。许多这些测量值可以通过一次正弦扫频完成,从而在保证卓越精度的同时缩短测试时间。失真测量包括谐波失真(THD、THD+N)、摩擦和嗡嗡声、松散颗粒检测、互调失真、非相干失真以及感知失真测量。 phrasing style and similar line lengths