为什么音频神经网络使用频谱图而不是波形?
波形在理论上保留了声音的全部信息,频谱图反而会引入一定的信息损失。但在实际的音频神经网络与机器听觉系统中,几乎所有主流模型仍然选择频谱图作为输入特征。这并不是简单的工程折中,而是由梯度下降过程中的数学结构所决定:神经网络在学习过程中天然对高频信息“迟钝”,而频谱图通过将时间信号映射到频率空间,在一定程度上消除了这种不均衡的学习偏置,使不同频段的特征能够被更均匀地建模与优化。
正因如此,这一原理也被广泛应用于工业声学与智能检测领域,例如异音异响分析、设备振动诊断与声学信号建模等场景。基于这一技术基础,苏州东原电子有限公司长期致力于声学研究与工程应用,专注于提供异音异响检测系统、声振测试设备、声学阻抗管定制,以及消声室与静音箱整体解决方案,同时推动声学新材料在工业与科研领域的应用与落地。
从波形到频谱图
一段声音在计算机中的原始记录方式非常简单:按固定间隔采集空气相对平衡压强变化的幅度,并通过采集设备转化成数字信号保存在计算机中。
波形保留了声音的全部信息,不考虑采集硬件引入的失真与采样率限制,其在信息上没有任何损失。但在音频深度学习的实践中,几乎所有主流模型,无论是故障检测、语音识别、音频事件检测几乎都不直接把波形喂给网络,而是先将其转换为频谱图或者频谱图的变体(例如梅尔频谱图、CQT)。
频谱图是对波形做短时傅里叶变换(STFT)的结果。具体来说,用一个窗函数 ω(τ) 在时间轴上滑动,每到一个位置 t ,就把窗内的信号做一次傅里叶变换:
X(t,f) 是一个复数,其模的平方 |X(t,f)|2 就是频谱图在时刻 t、频率 f 处的能量值。本质上,这把一维的时间序列展开成了二维的时间-频率平面。
STFT 不增加信息量,甚至会造成损失。窗函数和窗滑动步幅的选择会轻微丢失时域精度,此外现有网络通常使用傅里叶变换的模而非原始复数,相位信息也随之丢弃。根据马圣著名的第一性原理,以及“如无必要,勿增实体”的原则,似乎直接将波形喂给神经网络才是正途,何必多此一举?
频谱偏置:对高频迟钝的神经网络
神经网络在拟合函数时存在一个被广泛观察到的现象,称为频谱偏置:网络倾向于优先学习目标函数中的低频分量,而高频细节需要更长的训练时间才能逐步拟合。
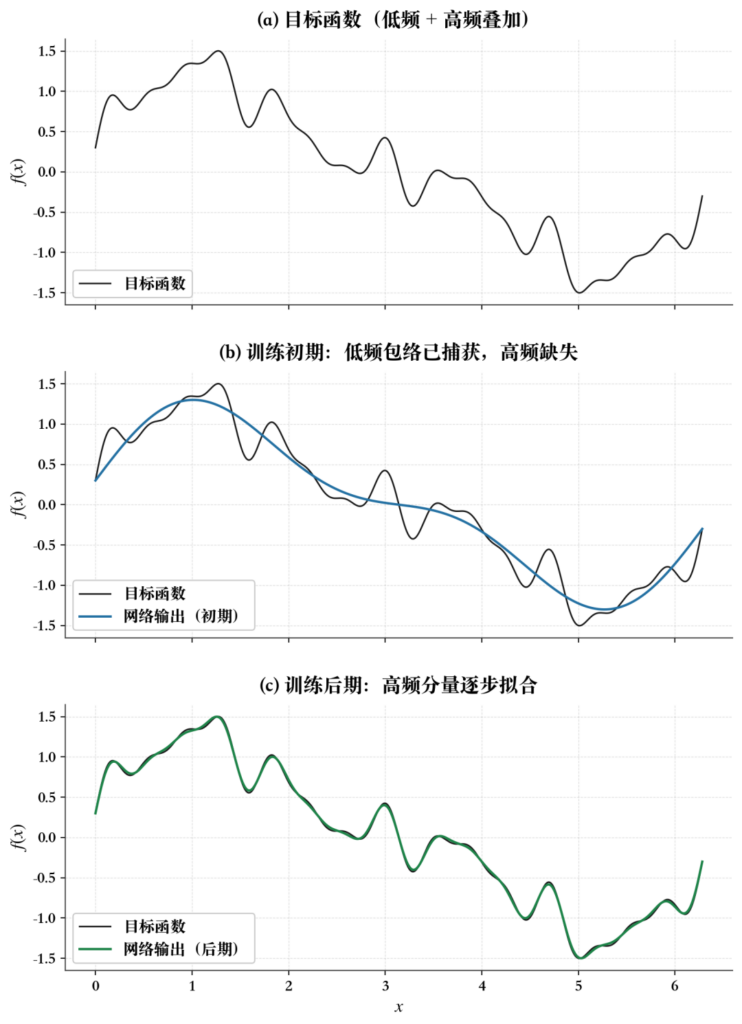
上图是一个简单的例子。目标函数(粉色曲线)由低频成分和高频成分叠加而成。训练初期(中图),网络输出(蓝色曲线)已经很好地捕捉到了整体走势,也就是低频包络,但高频细节完全被忽略,曲线看起来像是对目标做了一次平滑。训练后期(下图),网络输出(绿色曲线)才逐步开始拟合那些快速振荡的高频分量。
先学低频(宏观特征)再学高频(细节特征),在图像、文本等任务中往往是合理的,低频对应全局结构,高频对应边缘细节,优先级确实有高低之分。但音频不同:低频成分(50 Hz 以下)往往只是背景噪声,而真正承载信息的频段分布在从几百到上万赫兹的宽广范围内,并且和任务相关,并不存在“越低频越重要”的规律。
先学习低频不是偶然现象,而是梯度下降的数学结构所决定的。下面用一个简化的推导来说明原因。
高频分量与梯度衰减
设网络的输出为 f(x;θ),目标函数为 y(x),均方误差损失为:
训练的本质是通过梯度下降调整参数 θ 。对某个参数 θj 求梯度:
残差 r(x) 是网络输出与目标的差。训练初期网络输出接近零,残差近似等于 -y(x),即目标函数本身。
关键在灵敏度函数
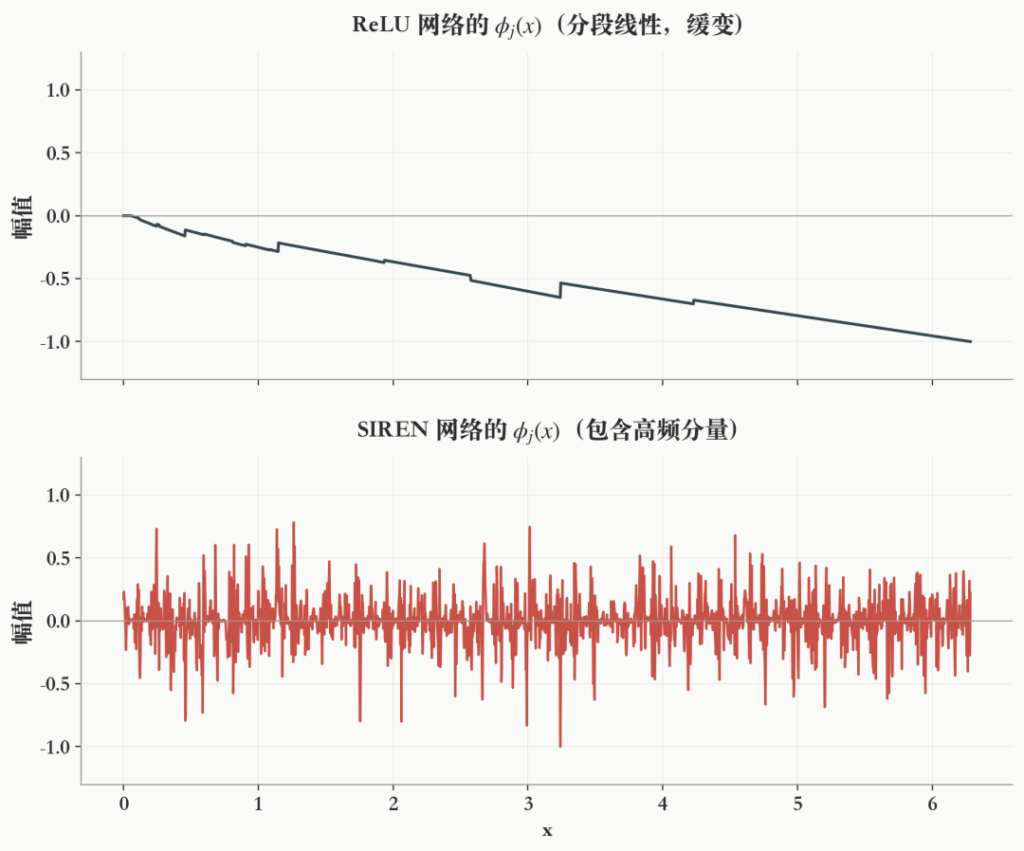
它描述“参数 θj 微调时,网络输出在各处如何响应”。对于常见的全连接网络和随机初始化,Φj(x) 是激活函数的复合,其通常不含高频振荡。
现在假设目标函数包含一个高频正弦分量 sin(ωx) ,ω 很大。它对梯度的贡献为:
由 Riemann–Lebesgue 引理,当 ω→∞ 时,一个缓变函数与高频正弦的积分趋于零:
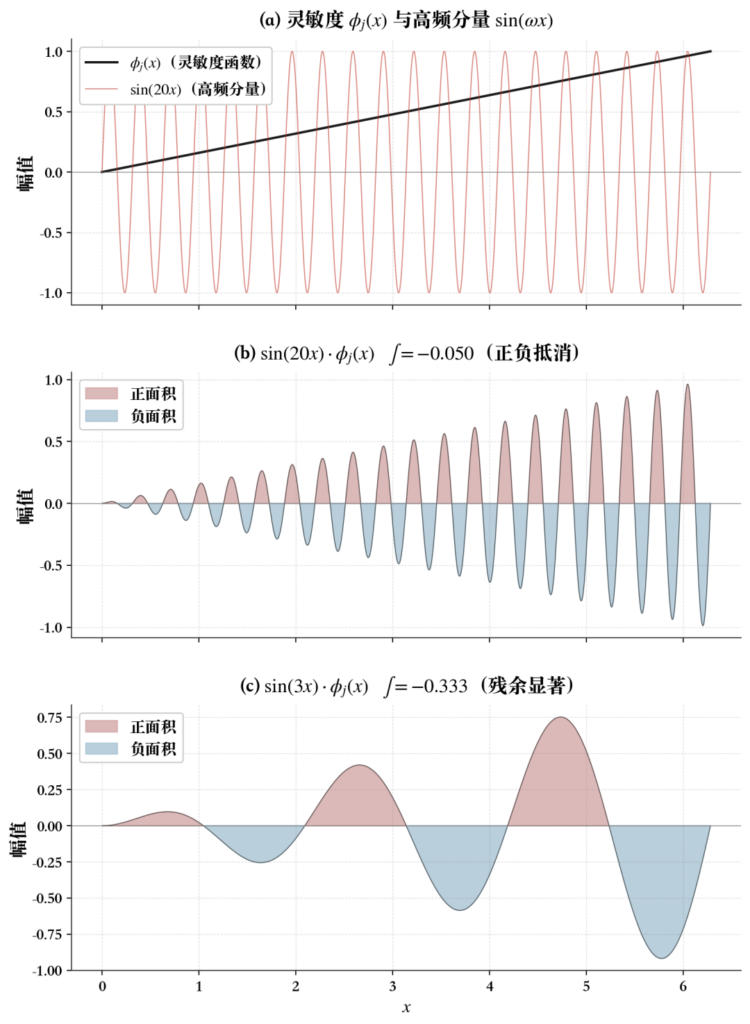
这很符合直觉(如上图所示)。高频的 sin(ωx) 在缓变的 Φj(x) 的每一小段上快速正负交替,正面积和负面积几乎完全抵消,积分接近零(中图)。而低频分量的振荡周期足够长,在 Φj(x) 变化的尺度上不会完全抵消,积分保留了显著的残余(下图)。ω 越大,抵消越彻底,这个频率分量对梯度的贡献就越小。
这导致梯度下降每一步更新时,低频残差在梯度中的贡献远大于高频残差。于是低频分量被迅速修正,高频分量的学习信号则淹没在数值噪声中,需要更多轮迭代才能缓慢积累起来。
频谱偏置并非意味着网络不能学习高频特征,只是比低频特征慢得多。有时候慢本身就是致命的:当高频梯度的量级落入浮点精度的噪声区间后,Adam 等自适应优化器会进一步压缩这些微弱梯度的有效步长,高频分量的参数更新实际上陷入停滞。此外,有限的训练预算也构成硬约束,低频分量可能在几百步内收敛,而高频分量需要的迭代次数可能高出一到两个数量级。
此外,即便真的学到了,也不一定是好事。在波形表示中,高频信息以极短时间尺度内的采样点振荡模式存在,网络要捕捉这些模式,就必须对时间轴上的精细变化高度敏感。但这种“对细节敏感”的能力与拟合采集噪声所需的能力是类似的:有意义的高频特征(如电机转动产生的谐波)和无意义的高频噪声,在波形中的呈现区别通常也很小。一个在波形上成功学到高频的模型,往往同时也学会了对噪声细节的过度响应,泛化性能随之下降。而在频谱图中,这个问题不存在,5000 Hz 的频点和 100 Hz 的频点在空间上只是不同位置,网络用同样的卷积核、同样的感受野去读取,学习高频不需要额外的细节敏感性,因此不携带泛化代价。
对音频意味着什么
之前的讨论以函数拟合为例,但频谱偏置的影响并不局限于回归任务。即使是故障检测这样的分类问题,网络输出只是一个类别概率,本身不含任何高频,但问题是一样的,网络要识别输入中的高频模式,前几层就必须学到能响应该频率的滤波器,而滤波器参数的梯度更新依赖输入信号与误差信号的互相关,面临的是同样的高频衰减效应。
音频波形本质上是大量正弦分量的叠加,人类可感知的频率范围跨越了 20 Hz 到 20000 Hz。当网络直接处理原始波形时,它必须从采样点的振荡模式中学习对各频率分量的特征提取,这恰好撞上了频谱偏置最不擅长的场景。
以电机故障检测为例。正常运转时,振动由转频(通常几十 Hz)及其谐波主导,能量集中在低频。当轴承外圈出现点蚀缺陷时,缺陷引发的周期性冲击会在特征频率处产生一组新的谐波峰,但这些冲击脉冲的幅度可能只有正常振动的几十分之一,在波形上完全淹没于低频主振动之中。网络面对的正是之前的困境:承载故障信息的高频冲击分量,在梯度积分中被系统性地抹平。而在频谱图上,这些故障特征作为新出现的水平亮线或边带调制清晰可辨,与正常频率分量在空间上自然分离。
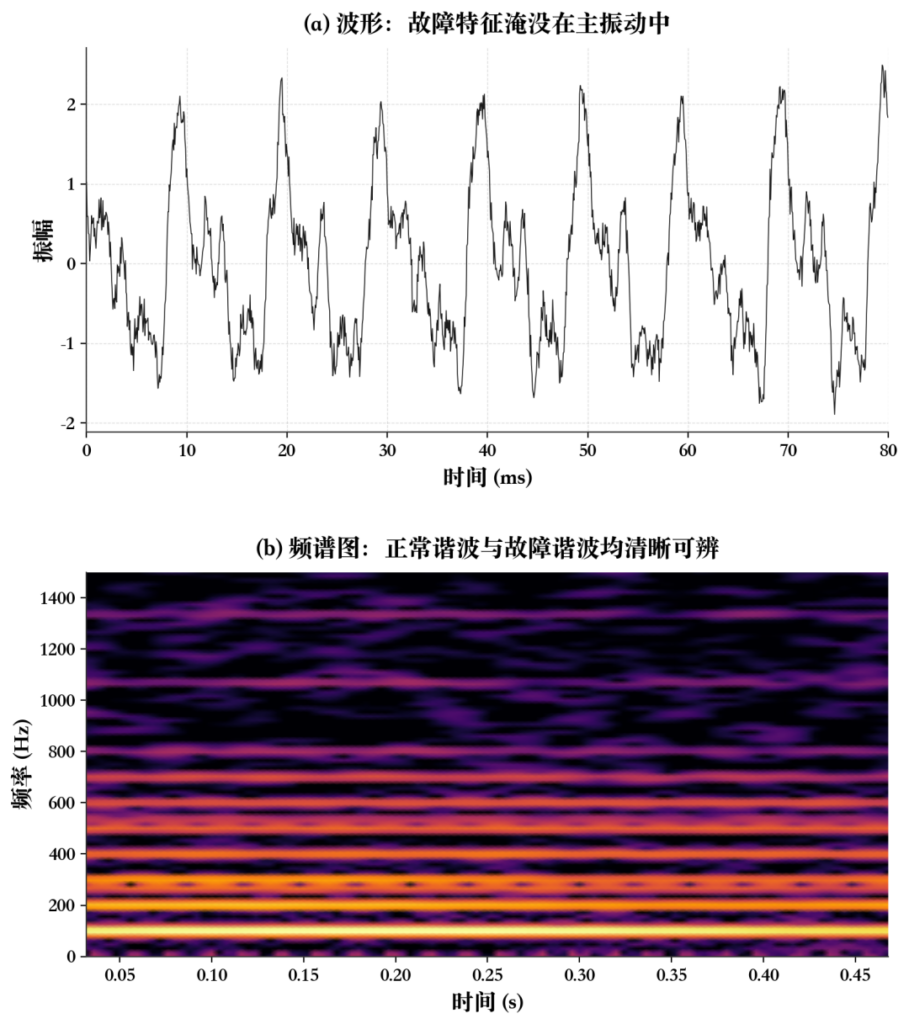
上图展示了这种对比。波形视角下只能看到复杂的叠加震荡,而频谱图将频率结构展开在二维平面上,哪些频段被激发,随时间如何演变更为清晰。
频谱图:拉平各频率的学习权重
前面已经推导过,波形中不同频率分量对梯度的贡献是严重不均等的。频率越高,权重越小。频谱图最直接的作用是消除不均等。
在波形中,“信号含有频率 f0”被编码为采样点以 f0 的速率振荡,f0 越高振荡越快,梯度信号越弱。STFT 将这个信息重新编码:频率不再体现为振荡速率,而是体现为频谱图上的空间位置,f0 的信息落在 f=f0 对应的那一行。频谱图送入 CNN 后,卷积核在二维平面上滑动,在标准卷积的假设下(忽略边界效应),每个空间位置接受的操作完全相同。反向传播时,所有频率 bin 获得的梯度权重在结构上是均等的。
位置编码与频段注意力
实际上也并非所有频段都同等重要。不同场景下不同频段的价值差异很大,标准卷积将它们等权对待,但同时也缺乏对频率轴语义的感知。
一些工作使用了多种机制在均等的基础上重新引入差异化。例如通过频段注意力机制,让网络自动学习对不同频段分配不同权重,或者直接在输入端做 Mel 频率尺度变换,以非均匀压缩的方式将特定任务的先验编码进坐标本身等等。
这些机制的共同逻辑是,先平衡梯度权重,再差异化。STFT 把各频率的梯度拉到同一起跑线,可学习模块再决定哪些频段值得重点关注。
直接操作波形的方案
频谱图是目前的主流选择,但并非唯一路径。一些工作选择直接在波形上操作,通过网络结构的设计来解决频谱偏置带来的困难。其中笔者认为最有意思的是 SIREN(Sinusoidal Representation Networks)神经网络,因为SIREN是正面的解法,它直接针对频谱偏置的数学根源来设计网络。
传统网络大多使用 ReLU 激活函数,其导数是分段常数,多层复合后灵敏度函数 Φj(x) 是缓变的低频函数,缺乏高频分量,这正是前面推导中梯度被抹平的根源。SIREN 将激活函数替换为 sin(ω0x):
其中 ω0 是控制激活函数振荡频率的超参数。对参数求导时:
导数本身就是一个以 ω0 振荡的周期函数。多层复合后,Φj(x) 不再是缓变的低频函数,而是包含丰富的高频分量:
此时再考虑高频目标分量 sin(ωx) 对梯度的贡献:
当 Φj(x) 本身包含频率 ω 的分量时,被积函数中会出现
这样的项,高频信号终于能在梯度中留下可观的贡献。
这是一个非常直接的方案,频谱偏置源于 Φj(x) 缺乏高频分量,那直接使用周期激活函数让它包含高频。但实践中 SIREN 有明显的局限。ω0 的选择非常敏感,太小则高频能力不足,太大则训练初期梯度剧烈振荡导致不稳定,不同任务往往需要反复调试。目前 SIREN 主要被应用于连续信号的隐式表征任务(如三维场景重建、图像拟合等),在音频分类和检测领域的探索相对有限。
其他路线
除了从激活函数入手,还有一些工作从其他角度绕开频谱偏置。但是通常要么通过数据量和训练来暴力解决,要么本质上还是频率分解。
例如 SincNet 将第一层卷积核参数化为 sinc 函数,即理想带通滤波器的时域形式:
其中 f1,f2 是可学习的截止频率。网络不再从零开始学习任意形状的滤波器,而是直接在带通滤波器的参数空间中搜索,第一层的输出本质上就是对输入的频率分解。这和频谱图的思路殊途同归,都是将“频率分解”这个先验注入网络。只不过 SincNet 让滤波器的中心频率和带宽由数据驱动,而非固定为均匀的傅里叶基。
wav2vec 2.0 和 HuBERT 用海量无标注音频做自监督预训练,前端是多层 CNN 直接处理波形。它们不试图从结构上解决频谱偏置,而是用数据规模和计算量来抵消其影响。训练足够久、数据足够多,高频特征终究会被学到,并且泛化性能也可以通过海量的数据来达到。这条路的代价是显而易见的:预训练需要数千小时的音频和大量 GPU 算力,对于工业故障检测等数据稀缺的场景,这个条件通常不具备。
这些方案各有适用场景,但共同点是都在以不同方式解决同一个问题。让网络具备对低频和高频的感知能力。频谱图用一个无参数的前端变换一步到位地解决了这个问题,不需要特殊的网络结构、不需要海量预训练数据、不需要调敏感的超参数,这也是它在实际应用中被广泛采用的原因。
注:马圣指伊隆·马斯克。实际上符合其所谓第一性原理的预处理方式应当是梅尔频谱图,人耳的耳蜗相当于一个频率分解器。
参考文献
- Rahaman, N., et al. “On the Spectral Bias of Neural Networks.” ICML, 2019.
- Sitzmann, V., et al. “Implicit Neural Representations with Periodic Activation Functions.” NeurIPS, 2020.
- Ravanelli, M. & Bengio, Y. “Speaker Recognition from Raw Waveform with SincNet.” IEEE SLT, 2018.
- Baevski, A., et al. “wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations.” NeurIPS, 2020.
- Hsu, W.-N., et al. “HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units.” IEEE/ACM TASLP, 2021.