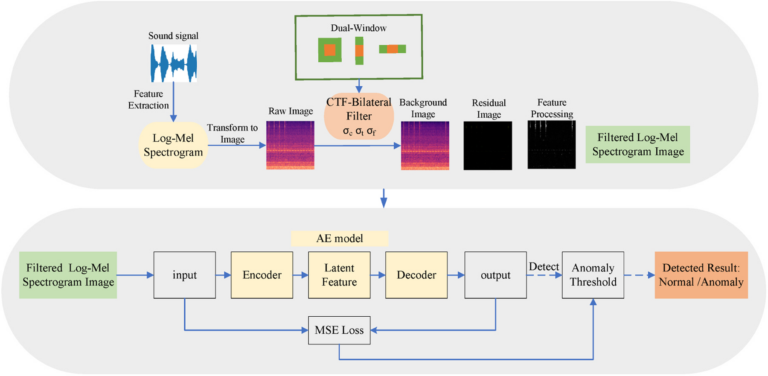
免训练异音检测方法解析:小样本工业异常声音检测新思路
论文:Towards Few-Shot Training-Free Anomaly Sound Detection
作者:Ho-Hsiang Wu, Wei-Cheng Lin, Abinaya Kumar, Luca Bondi, Shabnam Ghaffarzadegan, Juan Pablo Bello
机构:Bosch Center for Artificial Intelligence / New York University
发表:INTERSPEECH 2025
“免训练”的诱惑
工业异常声音检测有一个人尽皆知的痛点:数据是永远不够的,采集是没有尽头的。新机型上线没有历史录音,异常样本更是可遇不可求。无论是对于工厂中运转的设备状态监测,还是新产品的质检都是如此。
所以当一篇论文标题里同时出现”小样本”和”免训练”的时候,它的吸引力是真实的。这篇来自博世人工智能中心的论文提出了一个叫 AST-PB 的方法,承诺用不超过 10 条正常样本、不做任何训练,就能完成异常检测。
方法
方法比较简单,使用Transformer得到的特征代替传统特征来计算余弦距离:拿一个在大规模音频数据上预训练好的音频频谱图 Transformer(AST)[^1],冻结全部参数,把待检测音频和少量正常参考音频分别过一遍编码器,在 Transformer 选择的层中取出图块级别的隐层特征,逐图块算余弦距离,跨层平均,得到一张异常热力图,取分位数作为最终异常分数。
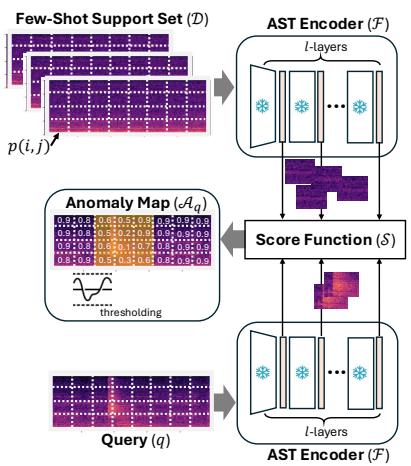
本质上就是一个基于预训练特征的最近邻异常检测。方法从视觉领域的 WinCLIP 迁移而来,去掉了语言分支(异常检测无需文本信息),只保留了频谱图块级特征比对的部分。
整个方法的技术决策集中在两个选择上:使用Transformer中哪一层的特征以及用什么分位数做阈值。这两个参数在一个小验证集上调好之后就固定不动,应用到所有实验中。
虽然方法简单,但如果效果好,简单就是优雅。
实验结果
实验覆盖五个数据集,横跨工业和医疗两个领域。基线是自编码器(AE),异常检测领域最基础的方法。
MIMII 数据集:AST-PB 用 10 条正常样本,调和平均 AUC 为 0.715。自编码器用全量训练数据得到 0.720。论文原文称之为”表现相当,有时甚至更优”。措辞没有技术错误,但换个说法也许更准确:一个动用了预训练 Transformer 全部 11 层特征的方法,和一个从零训练的浅层自编码器打了个平手。虽然”表现相当”,但也乏善可陈。
两个私有数据集(Kadia 和 Asthma):AST-PB 大幅领先自编码器。但 Kadia 的训练集只有 20 条,Asthma 只有 101 条。这种数据量下自编码器连正常分布都拟合不出来,拿它当基线没有区分度。总结起来就是在深度学习不适用的场景下领先了深度学习。
DCASE2024 竞赛开发集和评估集:最有说服力的测试场,因为数据量和难度都足够。在源域上,AST-PB(10) 的调和平均 AUC 分别为 0.535 和 0.562,而自编码器用全量数据训练分别为 0.650 和 0.715,差距一目了然。论文把叙述重心放在了目标域上,AST-PB(10) 在两个集合上均得到 0.580,确实高于自编码器全量训练的 0.503 和 0.506。
但 0.580 的 AUC 本身意味着什么?粗略换算到实际检测场景:大约每判对 6 个异常的同时会误判 4 个正常样本。这个精度放在任何一条真实产线上都不可能被接受。
目前DCASE 排行榜上的最优方法在目标域上分别达到 0.724 和 0.737(虽然也很难说达到了可用的程度, 但DCASE竞赛为了区分度,难度通常远大于正常产线的任务)。AST-PB(10) 与它们之间的差距不是”有待改进”,而是不在同一层面。当然,最优方法用了伪标签微调,也不算同一赛道。但这反而说明了训练步骤并不可有可无,它是性能的来源。
如果不止十条数据?
作者做了一个有价值的对比实验:把正常参考样本数从 1 增加到 80,观察性能变化,80个样本在一般情况下对于电机异音检测、NVH异响等现在需求旺盛的任务完全是可接受的范围。
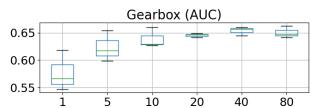
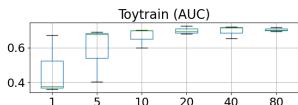
从论文的数据中可以看出对于齿轮箱和玩具火车两类设备判别任务的 AUC 在 5-10 条样本后就基本饱和,到 80 条时反而出现轻微下降。
作者将此归因为”图块比较在样本增多后变得更嘈杂”。这个归因是对的,但它凸显的矛盾可能更尖锐:方法有一个由其结构决定的性能上限,而且这个上限不高。
究其原因,论文使用的最近邻方法的检测能力完全依赖于特征空间中正常与异常样本的可分离性。当使用的是通用预训练模型的冻结特征时,这些特征并没有被优化来区分”正常运转”和”异常运转”。增加更多正常样本只会让正常图块的覆盖面更广,使得异常图块更容易在庞大的正常集合中找到一个”看起来还挺像”的邻居,反而压低了异常分数的区分度。此外当数据增多后, 特征空间中不同类别的形状将变得更不规则,而论文使用的简单百分位阈值方法无法表征这种不规则性。
对于可训练的方法,更多数据意味着更精确的决策边界;而对于 AST-PB,更多数据意味着更模糊的判断。这个差别是根本性的。
取长?取短?
如果把异常声音检测的技术路线画成一条光谱,一端是传统信号处理(手工特征和统计建模及固定阈值),另一端是端到端深度学习(从数据中同时学习学习特征和决策边界),AST-PB 站在中间,但是取两家之长的中间,还是集两家之短的中间并不好说。这可能取决于任务,如果确实只能拿到十个以内可靠的数据,并且不需要未来的升级扩展,并且六十多的准确率也够了,并且也能承受实际上和一个中等模型一样的推理成本,并且……,那也许可以尝试。
没拿到可解释性。 传统信号处理的核心优势是每一步都透明:资深工程师知道是哪个频段的能量出了问题,可以据此判断是轴承磨损还是齿轮松动。AST-PB 虽然能生成异常热力图,看起来在做类似的事情,但它展示的是 768 维隐空间中余弦距离的聚合结果,和原始物理信号之间没有可推导的对应关系。一位产线工程师看着这张图,通常无法做出任何有意义的维修决策。虽然热力图能大致指出异常分数来自频谱图的哪个区域,但这需要检测本身足够准确才有意义;而对于那些细微的异常,即便位置标对了,也无从直接推断物理原因。
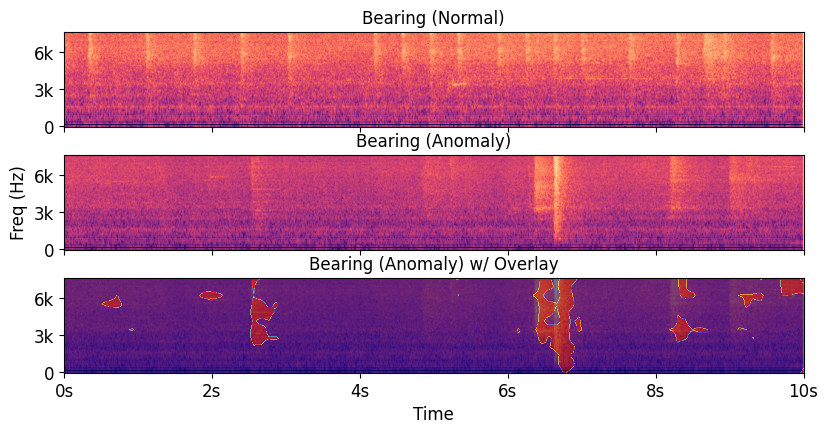
没拿到可训练性。 深度学习的核心优势是模型能从任务数据中持续学习,不断逼近最优决策边界。AST-PB 主动放弃了这个能力。它承担了深度模型的全部推理开销(完整的 Transformer 前向传播加大规模图块间余弦相似度计算),却把模型当作一个固定的特征提取器,不允许它从具体任务中学到任何东西。
也没拿到轻量性。 传统方法的另一个长处是部署代价低:一个高斯混合模型或者一组统计阈值可以跑在任何边缘设备上。AST-PB 每次推理需要将待测样本和全部参考样本过完整的 AST 编码器,再对 11 层乘以 1212 个图块乘以 N 个参考样本的特征矩阵做相似度计算。这不是一个能部署在嵌入式设备上的工作负载。
最终得到了什么?一个背着深度模型计算成本的方法,只有最近邻级别的判别能力,既没有传统方法的物理可解释性,也没有深度学习的任务适应能力。
超参数的隐性成本
方法自称”免训练”,但严格来说这不准确。它有两个必须调节的超参数:使用哪些 Transformer 层,以及分位数阈值取多少。作者在一个小验证集上选定了”全部层加 0.05 分位数”,然后在所有数据集上固定使用。
但作者自己的超参数实验清楚地表明,不同机器类型的最优分位数差异巨大,从 0.05 到 0.80 都有。固定一个全局值是为了实验公平性,这完全可以理解。但同一组实验中,允许逐设备调参的版本在 DCASE 评估集目标域上能把 AUC 从 0.580 提升到 0.677,接近 10 个百分点。
所谓”免训练”的方法在真正部署时仍然需要为每种设备单独标定阈值。而标定阈值又需要一个包含正常和异常样本的验证集。走到这一步,”免训练”的便利性已经所剩无几,条件可能已经够训练一个小模型了。
未来
作者在结论中提到的未来方向:一是探索更好的参考样本采样策略,二是引入数据驱动的网络来预测异常分数,三是对 AST 编码器做预训练和微调。
后两个方向一旦落地,方法就不再是”免训练”了。作者显然意识到,当前路线的性能瓶颈只有通过引入训练才能打破。这篇论文用自己的实验数据证明了”免训练”路线的天花板,然后在结论里承认了突破这个天花板的唯一途径是重新引入训练。
干净的反面参照
论文的实验工作量是切实的:五个数据集,跨工业和医疗,做了超参数分析和样本量消融。在极端低资源场景下,AST-PB 确实比从零训练的自编码器更稳定,这是预训练特征的合理用法。
但一个负责任的评估不能回避核心事实:方法在最基础的基线上勉强持平,距离实用精度有明显差距,增加数据不能改善,且方法结构决定了改善空间有限。它处于一个”概念验证可以,工程落地不行”的阶段。
但我完全能够理解作者,这篇论文像是在甲方或者老板既要又要又没数据情况下的产物。若不是迫于压力,谁愿意做这种一眼就不可能的研究呢。
对于正在评估异常声音检测方案的工程团队,这篇论文的价值也许不在于提供了一个可用的方法,而在于提供了一个干净的反面参照:仅靠冻结的预训练特征做最近邻比对,能走多远?
如果你的场景确实只有个位数样本、连训练一个小模型的条件都不具备,AST-PB 可以用来快速出一个基线数字。但只要条件允许哪怕最低限度的模型适配,这条路线就不值得坚持了。在传统方法和深度学习之间想走出第三条路,可能需要更有说服力的结果。
参考文献
- Y. Gong, Y.-A. Chung, and J. Glass, “AST: Audio Spectrogram Transformer,” INTERSPEECH 2021.
- K. Dohi et al., “MIMII DG: Sound dataset for malfunctioning industrial machine investigation and inspection for domain generalization task,” DCASE Workshop 2022.
- T. Nishida et al., “Description and discussion on DCASE2024 challenge task 2,” DCASE Workshop 2024.
- Z. Lv et al., “AITHU system for first-shot unsupervised anomalous sound detection,” DCASE2024 Challenge 2024.
- J. Jeong et al., “WinCLIP: Zero-/few-shot anomaly classification and segmentation,” CVPR 2023.
[^1]: 音频频谱图 Transformer(Audio Spectrogram Transformer, AST)是一种基于视觉 Transformer 架构的通用音频编码器,在 AudioSet 等大规模数据集上预训练,可提取通用音频特征表示。本文使用的是公开权重,共 11 层 Transformer,隐层维度 768。
综上,免训练与小样本框架在降低数据依赖方面展现出一定潜力,但其在复杂噪声环境与跨设备场景下的泛化能力仍有待进一步验证。相关方法若要走向工程化应用,仍需结合稳定的声学测量体系与系统级优化方案。基于此,可参考苏州东原推出的 谛听异音检测系统,以实现从算法研究到实际检测场景的有效衔接。