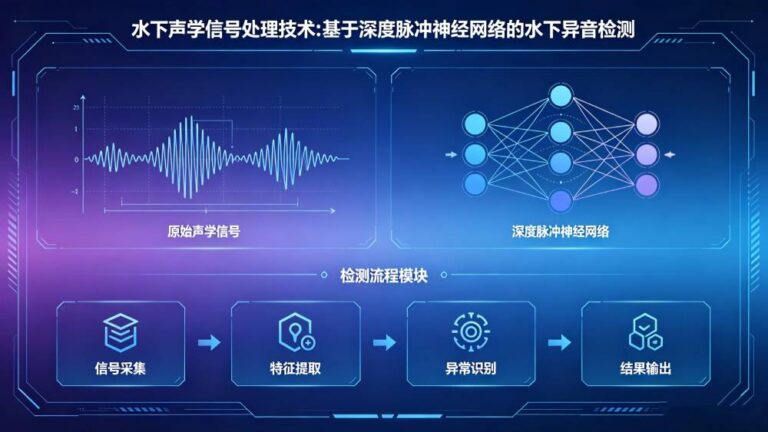
强噪车间如何做异音检测?非线性滤波+机器学习给出答案
一、 引言与研究背景
在“工业 4.0 ”与“维护 4.0 ”的大背景下,针对工业设备的预测性维护(Predictive Maintenance, PdM)已成为提升生产效率、降低停机成本的核心环节。异常检测(Anomaly Detection)作为预测性维护的关键技术,传统上高度依赖于为每台机器单独安装专用的诊断传感器(如振动、温度、电流传感器等)。然而,对于自动化程度较低、数量庞大的传统生产线而言,为每台设备配备昂贵的专用传感器在经济上并不现实。
基于声学数据(Acoustic Data)的异音检测提供了一种极具潜力的低成本替代方案。麦克风的安装成本低,且能够非接触式地收集机器的运行状态信息。由于机械故障(如轴承磨损、转速偏移、齿轮箱故障等)通常会伴随特定频率范围和声学谐波的改变,这些“故障签名”理论上可以通过声学分析被捕捉。然而,在真实的工厂环境中,存在一个致命的痛点:工业现场的背景噪声极其严重,有价值的机器故障声音往往被强烈的环境噪声所淹没(低信噪比,Low SNR)。这种复杂的噪声污染使得基于声学数据的异音检测变得异常困难。
为了解决这一行业痛点,Kaunas University of Technology 的研究团队 Yuki Tagawa 等人发表了题为《Acoustic Anomaly Detection of Mechanical Failures in Noisy Real-Life Factory Environments》的研究论文。该文提出了一种抗噪(Noise-tolerant)的深度学习方法论,创新性地将无迹卡尔曼滤波(Unscented Kalman Filter, UKF)与带有 Tikhonov 正则化(L2 正则化)的自编码器-解码器(Autoencoder-Decoder)神经网络相结合,显著提升了在真实强噪声工厂环境下的声学异音检测精度。
二、 核心挑战与 MIMII 数据集分析
为了验证模型在真实复杂环境下的性能,本研究采用了日立公司(Hitachi)发布的工业界权威声学数据集—— MIMII (Malfunctioning Industrial Machine Investigation and Inspection)。
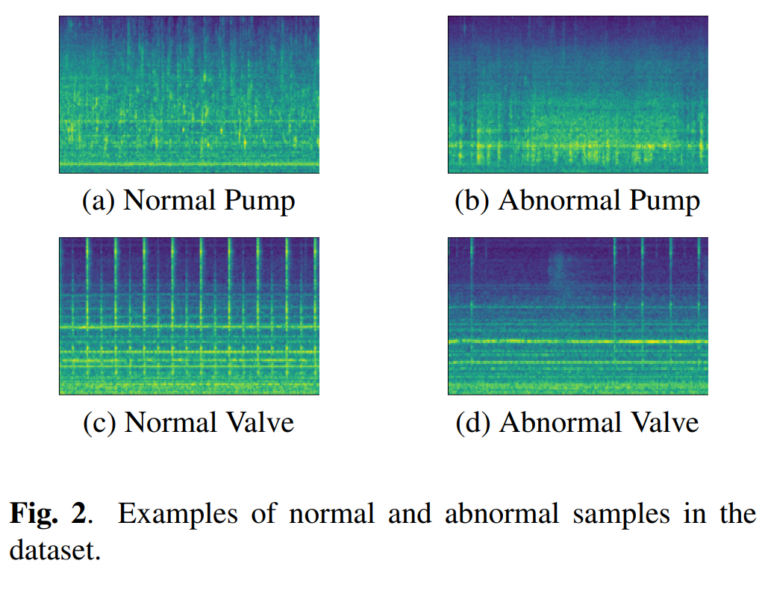
- 数据集特征: 该数据集包含了阀门、水泵(Pumps)、风扇和滑轨四种真实工业机械的运行声音。尤为关键的是,数据集中人为地混合了真实的工厂背景噪声,并设置了三个级别的信噪比(SNR):6 dB、0 dB 和 -6 dB。这种设置完美模拟了真实车间中不同程度的声学污染。
- 问题的无监督本质: 异常检测的固有难点在于,工业现场通常只能收集到海量的“正常运行”数据,而“异音(故障)”数据不仅极其稀缺,且类型未知。因此,该任务被严格定义为无监督的单类分类问题:模型只能利用正常声音数据进行训练,而在测试阶段需要识别出所有偏离“正常”模式的未知异常声音。
在本研究中,研究人员特别针对水泵(Pump,包含 ID00、02、04、06 四个型号)的数据进行了深入的实验与分析。
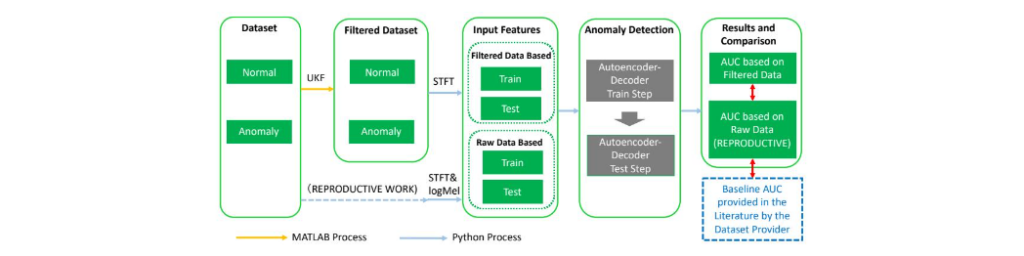

三、 研究方法与深度学习架构
本文的方法论涵盖了从特征工程、信号预处理到深度神经网络模型构建的完整技术栈。
1. 特征工程 (Feature Engineering)
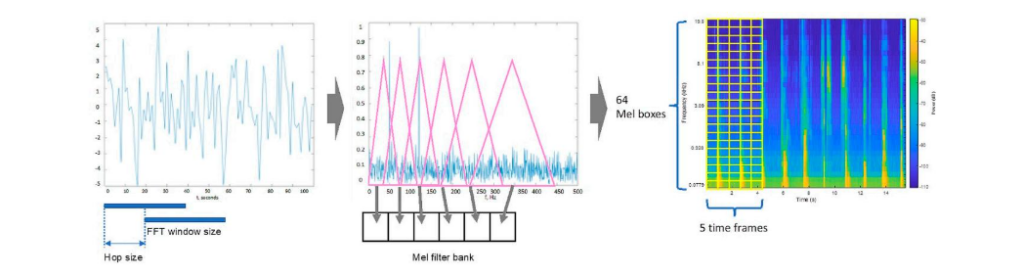
为了让神经网络能够有效处理一维的时域音频信号,研究团队对原始声音进行了时频域转换。具体而言,对每个长达 10 秒的音频片段(采样率 16kHz)进行快速傅里叶变换(FFT),随后提取对数梅尔频谱图 (log-Mel Spectrogram)。系统设置了 64 个梅尔滤波器,并将时间维度上的 5 个连续帧组合在一起,最终为自编码器构建了一个 320 维的高频特征输入向量。这种特征表示不仅包含了丰富的频率能量信息,也保留了短时的时间依赖性。
2. 非线性信号滤波与预处理:无迹卡尔曼滤波 (UKF)
在强噪声下提取信号,传统的线性滤波器(如高通、低通滤波器)容易在滤除噪声的同时误删关键的微弱异常特征。由于真实的工厂噪声通常是非高斯的,且机器声音的动态变化是一个非线性系统,作者放弃了传统的线性卡尔曼滤波(KF),转而采用了无迹卡尔曼滤波 (Unscented Kalman Filter, UKF) 进行状态估计与信号重构。UKF 利用无迹变换(Unscented Transformation, UT),通过一组确定性采样的 Sigma 点来近似非线性系统的后验概率密度分布,从而在非高斯、非线性噪声环境中实现了更精准的特征提取。
3. 带有 Tikhonov 正则化的自编码器-解码器
文章的基石检测模型是自编码器 (Autoencoder)。其核心逻辑是:仅用正常声音训练的自编码器能够完美重构输入数据;当输入异音时,由于网络未见过该模式,会产生巨大的重构误差(MSE),系统通过设定该误差的阈值来判定异常。
本文的核心理论创新在于,将信号处理领域中的 Tikhonov 正则化(对角加载)引入到深度神经网络的损失函数中。传统的自编码器通常单纯最小化均方误差(MSE)。但作者指出,在处理含有大量不可预测噪声的低SNR数据时,必须引入惩罚项以约束解的空间。通过在损失函数中增加 L2 正则化项(即能量最小化约束),模型在反向传播时被迫忽略那些方差极大、充满随机性的环境噪声成分,专注于重构工业机器底层本质的稳定声学成分。
四、 实验设计与深度对比分析
为全面验证所提方法,研究团队利用降维可视化技术以及多种基线深度学习模型进行了详尽的对比实验,所有评估均以 AUC(接收者操作特征曲线下面积) 作为核心量化指标。
1. 高维特征空间的降维可视化 (PCA vs. t-SNE)
研究首先对提取的 log-Mel 特征进行了主成分分析(PCA)和 t-SNE 降维可视化。
- 高信噪比 (6 dB) 场景下: 无论是 PCA 还是 t-SNE,正常样本与异常样本在二维潜空间中均表现出了较好的聚类分离,尤其是t-SNE能够清晰地画出两者的物理边界。
- 强噪声 (-6 dB) 场景下: 数据的分布变得极其模糊。尽管 t-SNE 勉强保留了部分的异常数据簇,但在正常与异常的交界处出现了大面积重叠。这一现象直观地证明了:在极低 SNR 条件下,传统的聚类算法已经失效,必须依赖深层非线性网络来提取更抽象的不变量。
2. 传统基线模型的脆弱性
- 重现 Autoencoder 基线: 作者首先使用 PyTorch 复现了 Hitachi 官方基于 Keras 的基线 Autoencoder。结果证实了原有的结论,即噪声极其严重地破坏了检测性能。例如,Pump ID 06 在 6 dB时的 AUC 高达0.9281,但在 -6 dB 的强噪下暴跌至 0.6518。
- 单类支持向量机 (OC-SVM): 作为经典的异常检测基线,OC-SVM 在强噪下表现出了极度保守的缺陷。对于异常数据的检测准确率在 -6 dB 下低至 0.56 到 0.58,完全无法满足工业界对高召回率的要求。
3. 对比复杂深度学习架构 (LSTM 与 AnoGAN) 的失效分析
文章进行了一项极具启发性的实验,尝试引入能够捕捉时序相关性的长短期记忆网络 (LSTM) 以及当前计算机视觉领域极为火热的生成对抗网络 (AnoGAN)。然而,结果出人意料:
- LSTM-Autoencoder: 在高信噪比(6 dB)下,LSTM 成功捕捉了机器声音的时序依赖,取得了高达 0.9537 的卓越 AUC;然而,在极端噪声(-6 dB)下,AUC 直接崩溃至 0.5941。作者敏锐地指出,在极低 SNR 下,时序信号中充斥着无规则的脉冲噪声,LSTM 强大的时序记忆能力反而导致它“记住了噪声”,无法提取任何有意义的机器状态信息。
- AnoGAN: 模型尝试将 10 秒的对数梅尔频谱图作为图像输入 GAN 进行异常生成测试。结果表现极差(AUC仅在 0.41 到 0.46 之间徘徊,甚至不及随机猜测)。研究分析认为,将包含了 10 秒钟巨量声学信息的庞大频谱图(640×480)强行压缩至 64×64 的图像像素,导致了关键短时频率特征的灾难性丢失;同时,10 秒的时间跨度对于捕捉极其短暂的异常瞬态而言过于宽泛。
4. 提出的融合模型的优越表现
最终,本文提出的核心架构——结合 UKF(无迹卡尔曼滤波预处理)与采用带有 L2 正则化(MSE with L2 Regularization)损失函数的自编码器——在最恶劣的 -6 dB SNR 环境下展现出了绝对的统治力。
实验数据表明,以难度极高的 Pump ID 06 (-6 dB) 为例,未加处理的原始基线模型 AUC 仅为 0.7633。而采用 UKF联合正则化损失函数后,AUC 稳定提升至 0.7909。在分析重构误差(Reconstruction Error)的案例时,该系统成功避开了高达 99% 的稳态背景噪音,仅在 00000077.wav 等存在微弱 2 秒周期性异响(Periodic peaks)的片段中给出了巨大的异常警报。
五、 研究亮点与核心结论
综上所述,本文为工业声学异音检测领域贡献了多项具有深刻价值的研究亮点与结论:
- 理论架构的深度融合: 论文跳出了单纯叠加神经网络层数的思维定式,创造性地将传统信号处理中的非线性状态估计滤波(UKF)原理与深度学习中反向传播的损失函数(引入 Tikhonov 能量最小化正则项)进行了数学上的桥接。实验证实,深度学习模型损失函数的设计必须与前端应用的自适应滤波器的工程设计理念高度一致,才能实现协同增强效应。
- 揭示了复杂网络在强噪下的局限性: 文章通过严谨的对比实验打消了学术界对复杂时序模型(如 LSTM)或生成模型(如 AnoGAN)的盲目崇拜。明确指出在低信噪比恶劣工况下,过度复杂的时域关联模型反而会因为拟合了随机噪声而导致泛化能力崩溃。相较而言,经过严密数学约束正则化的标准 Autoencoder 展现了更强的抗噪韧性。
- 巨大的工业应用前景: 本文成功验证了在不增加昂贵工业物联网(IoT)传感器硬件投资的前提下,通过对常规麦克风录制的强污染音频进行深度重构,即可准确拦截极其微弱的潜在故障。这种声学故障模式识别系统可以作为高风险工业企业管理者的早期预警系统,大幅缩减由于机器意外宕机而导致的巨额停工成本,是真正契合“智能工厂(Smart Factory)”诉求的先进方案。
六、 局限性与未来展望
作者在展现卓越成果的同时,也为未来的科研人员指明了深入探索的方向。针对在强噪环境下低秩特征提取不足的缺陷,未来的研究将聚焦于:
- 流形学习与局部邻域关系挖掘: 计划在自编码器的隐空间流形学习(Manifold Learning)中引入度量学习(Metric Learning)思想,并在损失函数中强化局部邻域关系的映射,以进一步聚拢正常数据、排斥微弱噪声异常。
- 短时特征的深层卷积探索: 鉴于 10 秒级全局数据的失效(如 AnoGAN 实验所示),未来将放弃大跨度的段落分析,转而探索针对极短时间窗口数据的深度卷积神经网络(DCNN),从而提升对工业机械瞬间瞬态冲击(Transient Shocks)故障的抓取敏锐度。此外,研究借鉴语音识别(Speaker Identification)中鲁棒的信号盲分离技术,也将是剥离工厂混合声场的一大潜力方向。
在实际工业生产中,复杂且强烈的环境噪声始终是制约异音异响检测效果的关键因素。单一算法往往难以在低信噪比条件下稳定识别异常声音,而融合信号处理与智能算法的方案则展现出更强的工程适应能力。针对这一挑战,苏州东原电子推出的谛听异音检测系统,通过优化声学采集与算法模型,在强噪环境下依然能够实现对设备运行状态的精准感知与异常识别。系统广泛适用于电机、产线设备及复杂工业场景,为企业提供稳定可靠的异音检测与预测性维护能力,助力提升生产效率与质量管控水平。
Y. Tagawa, R. Maskeliūnas, and R. Damaševičius, “Acoustic Anomaly Detection of Mechanical Failures in Noisy Real-Life Factory Environments,” Electronics, vol. 10, no. 19, p. 2329, Sep. 2021, doi: 10.3390/electronics10192329.