突破特征提取瓶颈:机器学习驱动的极速异音检测与识别
一、 引言与研究背景
在当今的智能系统和安全监控领域,音频异常检测(Anomaly Detection in Sound, ADS)已经成为一项具有关键意义的研究课题。异常通常被定义为偏离预期的正常行为模式的数据,在音频领域,这些异常可能预示着机器故障、恶意活动或枪击等危急事件。通过及时、准确地识别这些异常声音,系统可以辅助决策者有效预防潜在的安全危机,并在医疗健康监控、音频监控及产品质检等领域发挥重要作用。
本文针对《Anomaly Detection in Raw Audio Using Extreme Learning Machine》(基于极限学习机的原始音频异常检测)一文进行严谨的学术解读。当前学术界关于异音检测的研究多聚焦于无监督学习和深度模型(如自编码器、变分模型等)以提升分类性能,但在训练效率和模型复杂度上仍存在痛点。为此,本文研究团队创新性地引入了极限学习机(Extreme Learning Machine, ELM),以监督学习的策略对复杂声学环境下的原始音频进行异常检测,旨在打造一个兼具高识别率和极速训练能力的音频分析模型。
二、 文章主要内容剖析
本研究的方法论遵循了标准的机器学习 pipeline,主要涵盖数据集配置、特征工程、数据标准化、模型训练与评估五个核心环节。
1. 实验数据集介绍
为了确保实验的真实性和说服力,研究选用了具有高度挑战性的权威数据集——TUT Rare Sound Events 2017。该数据集共包含 2987 个音频文件,具有以下突出特点:
- 混合声学场景: 数据集将独立的目标异音与提取自 TUT 2016 真实声学场景的日常背景噪声进行了融合。这种混合生成技术不仅是一种数据增强手段,也真实模拟了现实世界中嘈杂的背景干扰。
- 多类别检测: 数据包含三个具体的异常类别:婴儿啼哭(Baby cry)、玻璃破碎(Glass break)和枪声(Gunshot),以及不含任何异常声音的常规背景音(None)。
- 数据划分: 研究严格采用 80% 的训练集和 20% 的测试集进行数据划分,其中训练集包含 2389 个样本,测试集包含 598 个样本。
2. 声学特征提取工程
面对复杂的原始音频信号,文章并没有直接输入波形,而是进行了一套极具针对性的声学特征提取。值得注意的是,特征提取仅在数据标签标注的“异常事件起始至结束(onset to offset)”的时间窗口内进行,这大幅剥离了无关噪声。研究最终提取了总计 29 个维度的核心特征:
- 梅尔频率倒谱系数 (MFCC – 20 维): 这是一种模拟人耳听觉特性的经典声学模型。它通过将对数功率谱在非线性梅尔频度尺度上进行量化和线性余弦变换,极大地保留了声音的关键声学特征。
- 音高 (Pitch – 2 维): 包括音高强度与频率。作为感知属性,它能够客观量化听觉上声音波动的频率高低。
- 强度与振幅特征 (Intensity, Amplitude, Energy, Power – 共 5 维): 涵盖了声波的能量、功率强度以及声压的空间和时间分布。
- 谐波噪声比 (Harmonics to noise – 2 维/1 维综合): 该参数量化了语音信号中周期性(谐波)与非周期性气流湍流(噪声)之间的关系,由于不同发声机理导致其数值存在显著差异,是区分各类声音的重要依据。
提取完成后,研究采用 Standard Scaler 对这 29 维特征进行了标准化处理。该方法通过减去均值并缩放至单位方差,将特征分布调整至均值为 0,成功缓解了由于异音长度变异带来的数据样本失衡问题,使得模型在后续训练中更容易收敛。
3. 极限学习机 (ELM) 架构与训练
研究的核心模型是基于 Keras 框架构建的极限学习机(ELM)。ELM 是一种前馈神经网络,其与传统神经网络(依赖反向传播)最大的区别在于:ELM 的隐含层节点参数是随机分配的,并且在训练过程中绝不更新。
这一颠覆性设计带来了巨大的优势:不仅赋予了模型极快(快数千倍)的训练速度,更从机制上有效缓解了慢速训练和过拟合的挑战,从而产生极佳的泛化能力。在本实验中,ELM 模型配置了 5 个密集层(Dense Layer),每层包含 128 个隐藏单元,并设置了 0.3 的 Dropout 层以抑制过拟合现象。整个模型包含 54,276 个参数。
三、 研究亮点
- 突破性的性能对比: 既往基于 TUT 2017 数据集的研究中,采用传统 MLP 架构的模型测试准确率仅徘徊在 64.1%;即便是采用 ELM 进行音频场景分类的研究,其准确率也只有 75%。并且有文献指出,ELM 结合 MFCC 特征在预测任务上能够超越传统支持向量机(SVM)5%,甚至超越部分经典神经网络 20%。本文的亮点在于通过精细特征与 ELM 的结合,将异常检测准确率推向了新高。
- 事件驱动的精准特征提取: 本文并未在整个音频片段上盲目提取特征,而是严格依据数据集中标记的“事件发生时段”提取数值。这一方法赋予了“None(无异常)”类别极高的区分度(特征值自动归零),为模型决策提供了清晰的物理边界。
四、 主要实验结论
在经过 150 个 Epoch、批次大小(Batch Size)为 10 的模型迭代拟合后,实验得出了具有重要学术价值的结论:
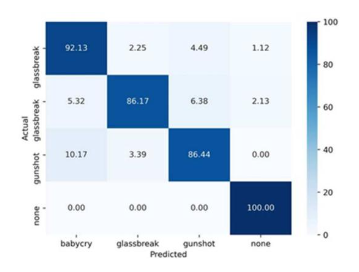
- 极高的检测准确率: 基于 ELM 的音频异常检测模型展示了卓越的分类性能,在训练阶段最高获得了 98.12% 的训练准确率,并在最终评估中取得了 93.98% 的整体异常检测准确率。
- 各分类表现卓越: 对于现实中极度敏感的婴儿啼哭(Baby cry)类别,模型的识别准确率达到了 92.13%,表现最为突出。对于玻璃破碎(Glass break)和枪声,其识别准确率也表现出了较强的鲁棒性;而对于无异常的背景音(None),基于前述特征工程设计的独特性,模型实现了 100% 的准确拦截。
- 结论表明,相较于复杂的深度学习无监督架构,融合多维经典声学特征的 ELM 模型不仅计算开销小,且在带背景噪声的原始音频异常识别中表现出极强的工业化落地潜质。
五、 局限性与未来展望
尽管 ELM 在当前数据集上取得了超 93% 的成功,但研究团队秉持严谨的学术态度,指出了本研究所面临的挑战:在 TUT 数据集中,声音片段的数据变异性极高,且样本数据本质上存在一定的不平衡。
为此,作者向后续科研人员提出了重要的建议:未来的研究应当引入生成对抗网络(Generative Adversarial Networks, GAN)等数据增强(Data Augmentation)方法。利用 GAN 来人为合成和扩充特定类别的异音样本,这不仅能够进一步克服高变异性带来的挑战,更是避免模型陷入过拟合或欠拟合的关键路径。
针对工业场景中的实际需求,苏州东原电子推出的谛听异音检测系统,通过优化声学采集与智能算法架构,实现对设备运行声音的快速分析与异常识别,在保证检测精度的同时显著提升响应效率。系统已广泛应用于电机、智能设备及产线检测等场景,为企业提供高效可靠的异音检测与质量管控解决方案。
R. N. E. Anggraini, Ainurrochman, and R. Sarno, “Anomaly Detection in Raw Audio Using Extreme Learning Machine,” Institut Teknologi Sepuluh Nopember, Surabaya, Indonesia, [Unpublished/Preprint].