告别标签依赖:基于自监督机器学习的工业异音检测新范式
一、 引言与研究背景
在工业4.0 与智能制造快速发展的当下,针对工业设备运行状态的实时监控与早期故障预警(即异常检测)已成为保障生产安全与效率的核心技术。尽管当前基于计算机视觉的异常检测算法在工业表面缺陷检测等领域占据了主导地位,但在许多实际应用场景中,由于遮挡或设备内部结构限制,光学摄像头往往无法捕捉到机器深层或内部的物理缺陷。为了弥补视觉检测的盲区,声学监控(Acoustic Monitoring)与异音检测(Anomalous Sound Detection, ASD)算法应运而生,成为工业健康管理系统中不可或缺的一环。
然而,与常规的机器学习分类任务不同,工业声学异常检测面临着极具挑战性的客观限制:异常样本严重缺乏且数据集极度不平衡。在实际工业生产中,设备绝大多数时间处于正常运转状态,故障(异常)情况极为罕见,且故障类型千变万化,难以穷尽。因此,现有的主流方法(如单类分类器、自编码器、生成对抗网络等)普遍遵循一个基础假设:模型在训练阶段只能接触到正常样本。其核心思想是,仅利用正常数据训练出的网络,在面对异常样本时将表现出较差的泛化或重建能力,从而根据误差将其识别为异常。
近年来,对比学习(Contrastive Learning)作为一种新兴的自监督学习范式,在机器学习社区引起了极大的关注。其核心机制在于通过拉近同一批次中同一图像的不同增强视图(正样本对)的表征距离,同时推远不同图像(负样本对)的表征距离,以此在无标签数据中学习到极具区分度的特征表示。以 SimCLR 为代表的算法已经在图像分类和图像异常检测中取得了媲美甚至超越监督学习的 State-of-the-Art 表现。然而,对比学习在声学异常检测领域的应用却是一片待探索的空白。其根本障碍在于,现有的对比学习模型高度依赖于特定领域的图像数据增强技术(如几何旋转、随机裁剪等),而这些空间几何变换完全无法直接迁移至包含时序与频率特性的音频数据中。
基于上述研究空白,麦吉尔大学(McGill University)与Mila人工智能研究所的Hadi Hojjati等人创新性地提出了一种基于对比学习框架的自监督声学异音检测算法。该研究首次将对比学习成功引入声学异常检测领域,通过设计专门针对音频信号的数据增强策略,在潜空间中实现了正常声音与异常声音的有效分离,为无监督声音异常检测提供了全新的解决思路。
二、 核心方法与模型架构解析
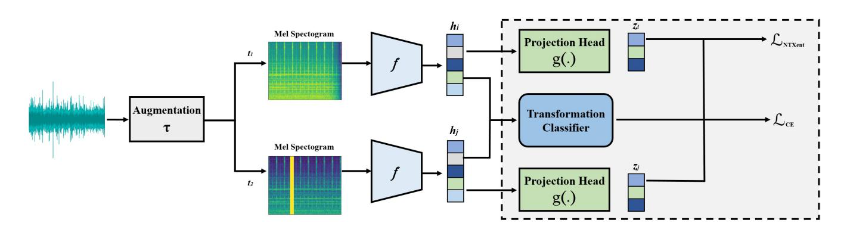
本文提出的算法框架严格遵循了对比学习的自监督学习逻辑,整个训练 pipeline 包含数据增强、特征提取、对比损失优化以及辅助任务联合训练四个核心模块。由于模型只能接触正常数据,其训练目标是让网络学会辨识正常声音样本中的细微变化与深层声学结构。
1. 面向音频的定制化数据增强策略 (Audio-specific Augmentations)
对比学习的成功高度依赖于数据增强策略的质量。增强操作必须在改变输入数据表面特征的同时,保留其核心的语义信息,避免产生冗余。为此,作者精心设计了一个包含7种不同变换的音频增强算子集合(𝒯):
- 音高平移 (Pitch Shift): 随机提高或降低音频的音高,范围设定在 [-10, 10] 个半音之间,概率均匀分布。
- 时间拉伸 (Time Stretch): 改变音频的播放速度(慢放或快进),速率范围为 [0.5, 2],随后重采样以保持原始输入长度。
- 白噪声注入 (White Noise Injection): 根据随机选择的信噪比(SNR,范围 [-6, 6]),向原始信号中注入高斯白噪声,以模拟真实工业环境的背景干扰。
- 淡入/淡出 (Fade In/Fade Out): 在信号的首尾添加不同包络形态(线性、对数、指数、正弦等)的淡入或淡出效果。
- 时间平移 (Time Shifting): 将音频信号向前或向后平移,平移量随机设定在 0 到信号总长度的一半之间。
- 时间掩蔽 (Time Masking): 随机选取一段极短的时间片段(小于总长度的 1/10)并将其置零,强迫模型从剩余时间序列中提取全局特征。
- 频率掩蔽 (Frequency Masking): 随机屏蔽频谱中的某一段频率成分(小于总频段的 1/10),提升模型对频率缺失的鲁棒性。
在训练过程中,系统会针对批次(Batch)中的每一个样本 xk,从上述集合中随机抽取两种不同的增强算子 t1 和 t2,生成两个相关的视图(正样本对)。
2. 频域特征表示与深层编码器 (Feature Extraction and Base Encoder)
原始一维音频信号经过数据增强后,研究将其转换为梅尔频谱图 (Mel Spectrogram)。梅尔频谱图是一种结合了时间与频率二维信息,且符合人类听觉感知特性的标准声学特征。具体参数设置上,研究采用了 128 个梅尔滤波器(Mel filters)、512 的跳跃长度(hop length)以及 2048 的 FFT 点数。
生成的二维梅尔频谱图随后被输入到一个基础编码器网络 f(·) 中,映射为低维的潜空间特征向量 hk。文章选取了经典的 ResNet-18 作为主干网络,并将最终全连接层大小修改为 512 维。尽管 ResNet-18 最初为自然图像分类设计,但既往研究表明,二维频谱图在纹理特征上与自然图像具有高度相似性,因此使用 ResNet-18 处理声学频谱图具有极高的效率和合理性。
3. 损失函数:NT-Xent 对比损失与辅助分类器
为了在潜空间中进行对比学习,网络在 ResNet-18 之后附加了一个由多层感知机(MLP)构成的投影头(Projection Head)g(·),将特征向量 hk 进一步映射至专门用于计算对比损失的子空间(维度为128)中得到 zk。
模型的核心优化目标采用了归一化温度标度交叉熵损失 (NT-Xent Loss)。该损失函数的数学本质是最大化正样本对(同一声音的不同增强视图)之间的余弦相似度,同时最小化与批次内所有其他负样本的相似度。通过这种“拉近同类、推远异类”的机制,模型被迫忽略数据增强带来的表层干扰,去挖掘正常音频底层最本质的声学不变量。温度超参数 τ 被设置为 0.07。
除了对比损失,文章还引入了自监督辅助任务 (Auxiliary Task) 的思想。在编码器输出 hk 的顶端,研究增加了一个简单的线性分类器,用于预测当前样本究竟经历了哪一种数据增强操作。通过将对比损失(NT-Xent)与辅助分类器的多分类交叉熵损失进行加权求和作为总损失,模型被迫在潜空间中保留更多关于变换过程的细节信息,从而进一步提升了特征表征的丰富度与鲁棒性。
4. 异常评分机制 (Anomaly Scoring Strategy)
在完成纯正常数据集的训练后,投影头 g(·) 会被丢弃,仅保留强大的 ResNet-18 编码器 f(·) 用于推断测试。对于任意输入的测试样本 x,模型提取其潜空间特征 hx = f(x),并计算其与正常训练样本分布的马哈拉诺比斯距离 (Mahalanobis Distance) 作为最终的异常得分 Sx:
其中,μ 和 Σ 分别为所有正常训练样本在潜空间中的均值向量和协方差矩阵。距离 Sx 越大,说明输入音频偏离正常分布的程度越严重,被判定为异常的概率越高。
三、 实验设计与性能评估
为了验证提出架构的有效性,研究基于真实的工业机械异音数据集 MIMII (Malfunctioning Industrial Machine Investigation and Inspection) 进行了严谨的实证分析。该数据集涵盖了风扇(Fans)、水泵(Pumps)、滑轨(Slide-Rails)和阀门(Valves)四类真实工业机器的 10 秒音频片段,采样率为 16KHz。
1. 对比实验与性能超越
研究以 ROC 曲线下的面积 (AUC, Area Under the Curve) 作为核心评估指标,并与基线自编码器(AE)、插值深度神经网络(IDNN)、VIDNN 以及 FREAK 等当前主流无监督模型进行了严格的横向对比。
实验结果令人瞩目:本文提出的基于对比学习的算法在所有四种机械类型上均实现了对对比算法的全面且显著的超越。
- 风扇 (Fan): 达到 80.11% 的 AUC,远超最好对比模型 VIDNN 的 66.5%。
- 水泵 (Pump): 达到 70.12% 的 AUC,优于 FREAK 的 62.4%。
- 滑轨 (Slide Rail): 达到 77.43% 的 AUC,超越 IDNN 的 67.8%。
- 阀门 (Valve): 实现了惊人的 84.17% AUC,而其它基于重构误差的自编码器模型在此类机器上表现极差(最高仅 59.0%,甚至接近随机盲猜的水平)。
2. 核心机理与深层物理现象分析
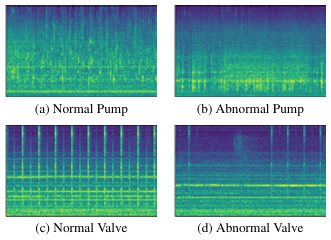
针对上述在“阀门(Valve)”类别上取得的颠覆性提升,作者给出了极具洞察力的解释。如图 2 和正常频谱图所示,阀门的声音具有高度重复的周期性模式。传统的基于自编码器(Autoencoder)的方法由于其本质是学习全局重建,很容易通过简单的信号拟合重构出这些重复背景,导致无论是正常还是异常的细微偏差,其重构误差都极小,最终导致检测失效。
相反,本文的对比学习网络在训练阶段,被强制要求在完全由正常样本组成的序列中,识别并区分被数据增强人为制造出的“微小差异”。这意味着模型学会了极度关注正常重复模式中的任何不一致性。当测试集中出现真正的异常样本时,即便它与正常样本共享大部分频率特征,但只要存在未在训练集数据增强分布中见过的模式破缺,就会被潜空间网络无情地映射到远离正常分布的区域。
3. T-SNE 潜空间可视化验证
为进一步验证特征的可分性,研究利用 T-SNE 技术对阀门(Valve ID 0)的潜空间嵌入进行了降维可视化分析。可视化结果清晰地显示(图3),即使在完全没有异常标签指导的无监督训练范式下,模型依然自发地将正常(Normal)样本和异常(Abnormal)样本映射成了彼此分离、界限分明的独立聚类簇。这从根本上证明了对比学习机制为声学异常检测构建了极具区分度的高维空间表达。
四、 研究亮点与核心贡献
- 开创性应用: 这是首批将自监督对比学习成功引入声学异常检测(Acoustic Anomaly Detection)领域的学术探索之一,有效打破了对比学习高度依赖图像几何增强的壁垒。
- 构建声学定制化增强策略: 摒弃了不适用于时序音频的图像裁切与旋转,系统性地构建并验证了包含音高平移、时间拉伸、白噪声注入及频时掩蔽等 7 种音频专属增强算子,为后续声学对比学习研究确立了范式。
- 多任务协同的表征强化: 将传统的实例判别(NT-Xent损失)与预测变换类型的辅助判别任务(交叉熵损失)相融合,使得模型在挖掘深度声学特征时保留了更加丰富的判别线索,有效提升了复杂机械环境下的检测上限。
五、 主要结论与未来展望
综上所述,Hadi Hojjati 等人的研究严密论证并证明了自监督对比学习不仅在视觉领域表现卓越,同样是一款解决声学异常检测痛点的强大工具。通过合理的音频数据增强与潜空间距离度量,该模型在 MIMII 工业数据集上大幅刷新了现有模型的性能上限(尤其是解决了自编码器难以处理周期性声音异常的顽疾)。
在未来的研究展望中,作者指出了一项极具潜力的改进方向:即少样本学习(Few-shot Learning)的引入。如果能在训练集中引入极少量的已知异常样本标签,将其整合到对比损失函数的惩罚项中,或者用于微调顶层的异常分类器,预计将进一步推动声学异常检测在复杂工业实景中的检测准确率向完美逼近。
在工业场景中,异常数据稀缺始终是制约异音检测技术发展的核心难题,而自监督学习为摆脱标签依赖提供了全新的解决思路。通过仅利用正常工况数据进行建模,系统能够在复杂环境中实现对异常声音的有效识别。基于这一技术趋势,苏州东原电子推出的谛听异音检测系统,融合先进声学感知与智能算法能力,可在多种工业设备运行条件下实现稳定的异音识别与状态评估,广泛适用于电机、精密制造及智能硬件等场景,为企业提供高效可靠的设备健康监测与预测性维护解决方案。
H. Hojjati and N. Armanfard, “Self-Supervised Acoustic Anomaly Detection Via Contrastive Learning,” in ICASSP 2022 – 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 2022, pp. 3253-3257.